Caro(a) estudante,
Atualmente, o setor de jogos eletrônicos é considerado o mais rentável da indústria do entretenimento, superando até mesmo o cinema e a música. Todavia, deseja-se crer que os jogos vão além de simples números, mas uma representação da autoexpressão do homem que, ao que tudo indica, é uma síntese dialética entre o lúdico e a tecnologia. Dessa forma, a dimensão multifacetada e multidimensional dos jogos permite discutir tópicos que vão além da ludicidade, propondo um estudo interdisciplinar de áreas como programação, psicologia, matemática, design, antropologia, e assim por diante. Neste âmbito, a dimensão da tecnologia é um pilar importante no que tange à inovação e implementação de novas abordagens em uma indústria altamente dinâmica. Dessa forma, nesta unidade de ensino, discutiremos tópicos importantes para compor os conceitos da inteligência artificial como uma área em constante desenvolvimento, sendo usada para resolver uma série de problemas e possíveis soluções no desenvolvimento de jogos eletrônicos. Então, inicialmente, discutiremos a importância da lógica fuzzy como uma dimensão da lógica booleana; buscando uma base para discutir as principais vertentes do aprendizado de máquina.
Bons estudos!
Embora seja temerário fazer generalizações, deseja-se crer que a injunção tecnológica foi capaz de reorientar todas as dimensões da práxis social, promovendo uma pluralidade de concepções que, doravante, está evidenciando o início de uma nova era apoiada na convergência entre as áreas da ciência. Nesse sentido, é importante notar o papel dos principais conceitos que permeiam a ciência em áreas que, à primeira vista, podem parecer não compatíveis com sua aplicação; por exemplo, os jogos eletrônicos, que, a partir da subjetividade do homem, foram capazes de inaugurar uma era que, inicialmente, era condicionada a uma limitação tecnológica (BEHESHTI, 2013; CERRI, 2014; BRITO, 2018).
Os jogos eletrônicos eclodiram a partir do advento das novas tecnologias, pautando-se na convergência entre ideias dos precursores desta nova era, ou seja, ideias dos diversos autores, professores, programadores e profissionais técnicos que estudavam os jogos eletrônicos, cuja essência, na época, encontrava-se difundida na criação e implementação de abordagens da ciência da computação, como a inteligência artificial (IA).
Nessa época, a fronteira da consciência artificial passou a ser vista como um conceito tangível, deixando de ser um campo exclusivo da reflexão filosófica. Há de se considerar, ainda, que o avanço no estudo do mecanismo de funcionamento do cérebro humano foi a base para o desenvolvimento das redes neurais artificiais, da IA e do aprendizado de máquina (LUGER, 2004, ROSA, 2008), conceitos que serão discutidos ao longo dos tópicos subsequentes. Nesse sentido, conforme se pretende mostrar, é possível identificar alguns conceitos importantes e promissores que são aplicados na indústria dos jogos eletrônicos, como fundamentos que compõem a IA.
Retornando à questão da subjetividade, de acordo com Tanscheit (2007, p. 2), os “seres humanos são capazes de lidar com processos bastante complexos, baseados em informações imprecisas ou aproximadas”, por exemplo, Karlsson (2005a, p.22) aponta que os humanos “fazem uso de termos como 'pouca força', 'muito longe' ou 'bastante apertado'” como elementos descritivos que definem uma determinada situação. Observe, portanto, que a percepção e interpretação das informações é uma dimensão humana, que trabalha a subjetividade.
Assim, como trabalhar com estados imprecisos e vagos quando há conhecimento insuficiente para representar o raciocínio humano por abordagens de controle? A teoria matemática de conjuntos fuzzy e lógica fuzzy, como extensões da teoria clássica dos conjuntos e da lógica formal, são abordagens que podem ser utilizadas para representar, em termos matemáticos, os dados e informações imprecisas de um determinado contexto (FACELI et al., 2011; RABIN, 2015).
Falando noutros termos, a essência da teoria fuzzy é trabalhar com situações que exigem respostas que vão além do clássico "sim" ou "não", mas situações em que termos como "talvez", "possivelmente", "provavelmente", "praticamente" e outros semelhantes são mais adequados para descrever processos, sistemas, estados, objetos, e assim por diante (LUGER, 2015). De fato, Tanscheit (2007) apresenta que a teoria fuzzy é uma abordagem que permite descrever conceitos que operam nas incertezas e imprecisões do mundo real, sendo uma teoria com alto grau de compatibilidade com a representação de estados dos personagens em jogos eletrônicos.
A lógica Fuzzy consegue então representar problemas de uma maneira similar à maneira com que humanos pensam sobre eles, pois conceitos (termos) como longe e pouco não são representados por intervalos discretos, mas por conjuntos Fuzzy que permitem que um valor pertença a vários conjuntos com diversos graus de pertinência. Por exemplo, um certo personagem de um jogo pode ter seu estado emocional pertencente ao conjunto feliz com grau de pertinência 0.7 e ao conjunto frustrado com grau 0.5 (ZADEH, 1965 apud TANSCHEIT, 2007, p. 22).
De acordo com Tanscheit (2007), os primeiros trabalhos sobre a lógica fuzzy são datados da década de 1960, elaborados pelo professor, matemático, engenheiro eletrônico e cientista da computação Lotfi A. Zadeh. Zadeh sustentava que desde os primórdios da computação, os pesquisadores passaram a trabalhar com situações de natureza biológica, sendo incapazes de modelar determinados eventos com os recursos teóricos e tecnológicos da época.
Idealmente, de acordo com Cavalcanti et al. (2012), o professor Zadeh publicou em 1965 na revista
Information and Control
um artigo denominado de "
Fuzzy sets
" (ZADEH, 1965), propondo uma descrição matemática para trabalhar com situações ambíguas, próximas à lógica humana. Partindo dessas premissas, conforme discute Tanscheit (2007, p. 22), “sua versatilidade faz dela uma excelente opção para aplicações que têm um certo grau de incerteza ou que necessitam de grande flexibilidade e capacidade de adaptação”. De certo modo, o pesquisador Lotfi A. Zadeh deu origem a uma teoria em que é possível modelar situações adversas e pouco casuais, implementando algoritmos para compor, por exemplo, o estado emocional de um personagem de um jogo eletrônico.

No âmbito dos jogos eletrônicos, desde que foi introduzida a discussão sobre a aplicação da lógica fuzzy no desenvolvimento de games em 1996 por O’Brien (1996) na revista Game Developer Magazine, verifica-se que a teoria do professor Lotfi A. Zadeh passou a ser uma das principais abordagens de IA utilizada por desenvolvedores. Convém lembrar, em primeiro lugar, que a lógica fuzzy – ou lógica difusa – é um desdobramento de IA, que pode auxiliar no desenvolvimento de praticamente todos os jogos modernos.
Mccuskey (2000), Karlsson (2005b) e Pirovano (2012) sugerem que a lógica fuzzy se revela como uma referência importante para, por exemplo, implementar máquinas de estados e sistemas que precisam lidar com a tomada de decisões dos personagens não jogáveis (NPC, do inglês: non-player character ), como a escolha de determinados artefatos – armaduras, armas, poções, habilidades, etc –, análise e seleção das melhores estratégias em contextos distintos – ameaças, objetivos, missões, controle de unidades, ataques, etc. –, ou mesmo na classificação de personagens jogáveis e não jogáveis em termos de atributos ou características, como a estamina, saúde, energia e mana, além do cálculo para definir o comportamento do NPC baseado na distância de uma ameaça. Por exemplo, com base no alcance de uma arma no jogo, é possível selecionar uma arma para ataque corpo a corpo, à distância ou fora de alcance – quando o NPC não tem nenhuma arma para atacar em uma determinada distância ou a arma do personagem jogável não tem alcance para o evento atual, conforme ilustra a Figura 1.
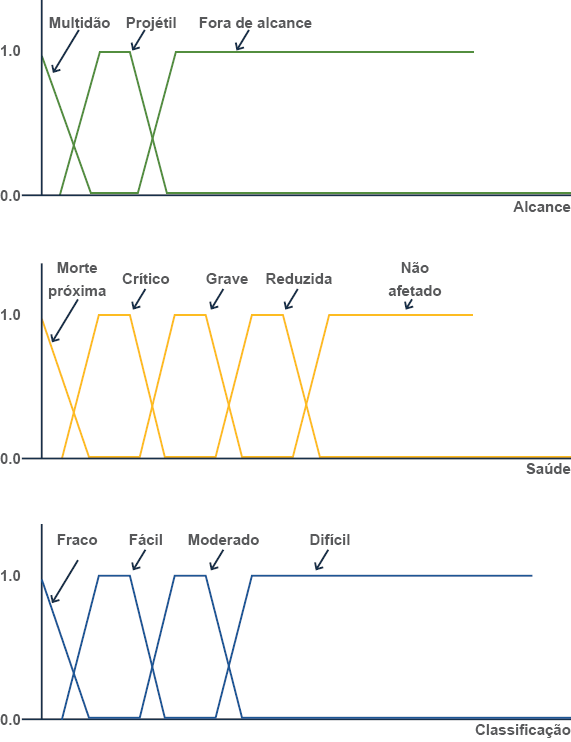
#PraCegoVer : A figura 1 demonstra as faixas que compõem as variáveis fuzzy em um jogo. Elas são representadas por linhas que se cruzam dentro de dois eixos verticais, marcando 0 e 1. A primeira faixa, na parte superior, representa a faixa difusa de uma arma. As duas linhas sobem e descem entre os limites de 0 e 1 se cruzando duas vezes, para depois se manterem constantes uma em zero e outra em um. No início da descida da linha superior está uma seta com a palavra multidão, no primeiro cume uma seta com a palavra projétil e assim que a linha se mantém constante na parte superior, há uma seta com a palavra fora de alcance. No final da linha constante inferior, há a palavra alcance. A faixa do centro representa a saúde difusa de um NPC. As duas linhas se cruzam 4 vezes para depois se manterem constantes. No início da descida da linha superior há uma seta com a expressão morte próxima; no primeiro cume, uma seta com a palavra crítico; no segundo cume, a palavra grave; no terceiro cume, a palavra reduzida e na linha superior constante a expressão não afetada. Na linha constante inferior, há a palavra saúde. Por fim, a última faixa, na parte inferior, demonstra a classificação difusa de avaliação um jogador. As linhas se cruzam três vezes. No início da descida da linha superior há uma seta com a palavra fraco; no primeiro cume, uma seta com a palavra fácil; no segundo cume, a palavra moderado e na linha superior constante a palavra difícil. Na linha constante inferior, há a palavra classificação.
Nos subtópicos subsequentes serão discutidas as principais vertentes que compõem a lógica fuzzy. Para tanto é necessário comparar, ou melhor, realizar uma pequena recapitulação da lógica clássica, de modo a se entender os conceitos e aplicações lógica fuzzy no âmbito da inteligência artificial.
Em primeiro lugar, precisamos considerar que a teoria fuzzy trabalha diretamente com as premissas que compõem a lógica matemática; isto é, uma dada função lógica pode ser representada por uma forma normal conjuntiva ou disjuntiva. Esmiuçando um pouco mais, verifica-se que a função lógica clássica pode representar os cálculos das operações proposicionais – conjunção (&&), disjunção (||) e negação (!) –, usando uma tabela verdade para avaliar dois valores lógicos (A e B), em que 0 retorna um valor FALSO, enquanto um valor diferente de zero retorna VERDADEIRO. Por exemplo:
Operador && (E) - Conjunção
0
1
0
0
0
0
1
0
0
1
1
1
A
B
A && B
Operador || (OU) - Disjunção
0
1
0
0
0
0
1
0
0
1
1
1
A
B
A || B
Operador ! (NÃO) - Negação
A
1
0
0
1
!A
Tanscheit (2004) comenta que na teoria clássica dos conjuntos, quando utilizada em uma condição que exija a definição exata dos predicados, não é possível trabalhar com respostas diferentes de verdadeiro ou falso. Dessa forma, verifica-se que a relação entre um determinado elemento de um conjunto – pertinência – fica bem definido no contexto da lógica clássica. Por exemplo, no contexto dos jogos digitais, podemos verificar que dado um conjunto C – constituído apenas por elementos que representam tipos de habilidades, como fogo, água, recuperar vida, velocidade, etc – em um universo qualquer U, os elementos que constituem o universo U podem assumir apenas os valores: VERDADEIRO ou FALSO. Mas, por quê? Idealmente, a álgebra booleana – ou lógica de Boole – opera apenas com os valores 0 e 1, classificando o grau de pertinência da variável observada. Noutros termos, os elementos do universo U pertencem (u=0) ou não pertencem (u≠0) ao conjunto A – ou seja, os elementos do universo U só podem pertencer ao conjunto A se forem classificadas (Verdadeiro) como um tipo de habilidade. Em síntese, podemos expressar tal premissa pela função f c , em que os conjuntos são denominados "crisp" (TANSCHEIT, 2004; CORCOLL-SPINA, 2010):

#PraCegoVer : Dado um conjunto C em um universo U, os elementos deste universo pertencem ao conjunto C se e somente se U for igual a 1; ou não pertencem ao conjunto C se e somente se U for igual a 0.
Já na lógica fuzzy, em vez de trabalhar com os valores verdadeiro ou falso para representar o grau de pertinência de uma variável, são utilizados diferentes graus de pertinência para assumir quaisquer valores definidos em um conjunto infinito entre um intervalo [0,1] (ZAROZINSKI, 2002). Observe, portanto, que ao contrário da lógica clássica, não é possível representar as operações lógicas na forma tabular – tabela verdade –, mas são expressos por funções:
» Clique nas setas ou arraste para visualizar as imagens
Retornando à questão do nosso conjunto C – constituído apenas por elementos que representam tipos de habilidades –, na lógica fuzzy, de acordo com Tanscheit (2004), o conjunto C em um universo U pode ser expresso pela função de pertinência:
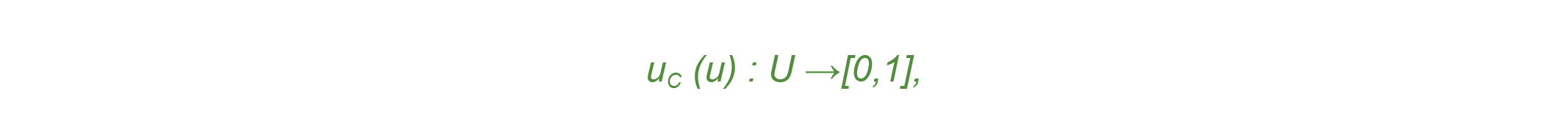
#PraCegoVer : Um conjunto fuzzy C em um dado universo U pode assumir um valor infinito no intervalo entre zero e um.
Também expresso por uma função que representa um conjunto de pares ordenados:

#PraCegoVer : Um conjunto fuzzy C é expresso por uma função que representa um conjunto de pares ordenados, onde a função de pertinência do universo U incida o quanto o universo C é compatível com o conjunto A.
Em que:
» Clique nas abas para saber mais sobre o assunto
Representa o conjunto fuzzy.
Expressa a função de pertinência, indicando que u é compatível com o conjunto C.
Representa o universo observado – também denominado de universo de discurso.
De acordo com Tanscheit (2004, p. 3), no âmbito da lógica fuzzy, “um determinado elemento pode pertencer a mais de um conjunto fuzzy, com diferentes graus de pertinência”. Como um exemplo simples, imagine que em um determinado jogo, a IA precisa controlar um sistema de mísseis, calculando possíveis obstáculos usando a lógica fuzzy. Como poderíamos trabalhar com a situação descrita? Primeiramente, a IA deve tomar uma decisão utilizando diferentes graus de pertinência. Para tanto, é necessário dividir o conjunto [0,1] em intervalos, em que:
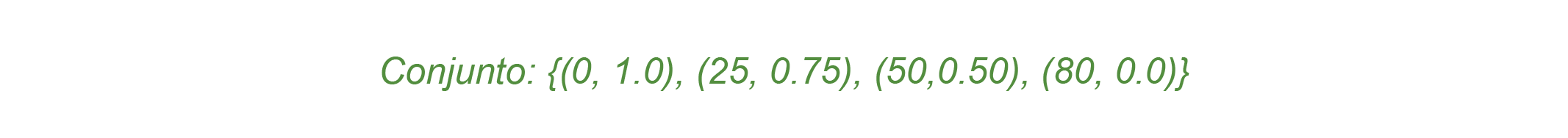
Onde:
Na lógica fuzzy, observa-se que para expressar formalmente uma determinada sentença, é necessário basear-se em palavras e não em números (TANSCHEIT, 2004; ZAROCINSKI, 2002). Nesse sentido, aliás, verifica-se que a lógica fuzzy introduz o conceito de variáveis linguísticas, cujos valores são representados pela linguagem natural, em termos específicos. Portanto, uma variável fuzzy pode ser descrita por um dado conjunto (A, X, B), onde A representa o nome da variável, X é um conjunto universo, B é um conjunto fuzzy no universo X (COPIN, 2010).

Argumenta-se cada vez mais hoje em dia que o setor de jogos eletrônicos é um dos mais dinâmicos e receptivos a novas tecnologias e abordagens inovativas. Dessa forma, iniciando a nova geração de videogames em 2020, verifica-se que a indústria de games, como a mais rentável dos setores do entretenimento, é sem dúvidas, uma das principais a implementar conceitos multifacetados da Inteligência Artificial. Sendo assim, no momento, portanto, as tecnologias inovativas e abordagens de Inteligência Artificial, aprendizado de máquina e redes neurais são parte integrante da indústria de jogos eletrônicos. Em outras palavras, conceitos antes empregados em outros setores, como a lógica fuzzy e redes neurais são amplamente utilizados em jogos e soluções gamificadas. Para saber mais sobre esse assunto, leia o artigo "Aplicação de Lógica fuzzy e Redes Neurais em Jogos Computacionais", de Pereira, Pozzebon, Frigo e Santos (2016), no link:<
https://bit.ly/3n0pSex
>.

Apesar dos conjuntos enfatizarem normalmente o uso dos números para representar os valores de um determinado estado, a lógica fuzzy utiliza as variáveis linguísticas como uma representação que obtém valores de um dado conjunto de palavras; corroborando com a premissa de Lotfi A. Zadeh, em que definir o valor de uma variável em linguagem natural, sem valores numéricos, é mais natural para os seres humanos. (TANSCHEIT, 2004; NILSSON, 2014; HURWITZ e KIRSCH, 2018).
Corcoll-Spina (2010, p. 66) aponta “é aquela cujos valores são subconjuntos fuzzy, que correspondem por sua vez a termos linguísticos. Podemos dizer que uma variável linguística é um substantivo enquanto seus valores são adjetivos”. Dessa forma, por exemplo, variáveis linguísticas como "velocidade", “temperatura” e “altura”, podem assumir valores como: “muito baixo”, "baixo", “médio”, “alto” e “muito alto”. Conforme nos lembra Tanscheit (2004), “estes valores são descritos por intermédio de conjuntos fuzzy, representados por funções de pertinência”, conforme ilustra a Figura 2.
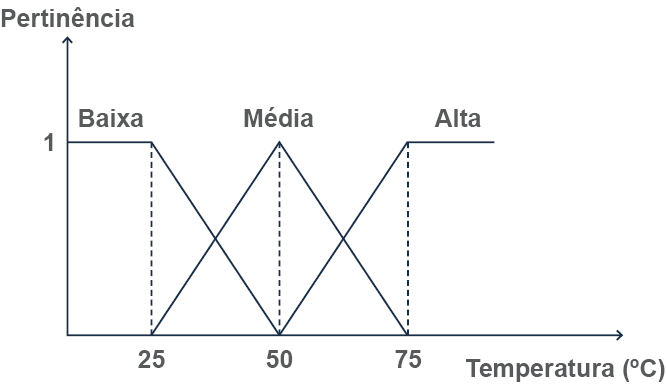
#PraCegoVer: A figura 2 demonstra as funções de pertinência para uma data variável (temperatura) em um gráfico que usa as seguintes variáveis linguísticas: baixa, média e alta. O eixo horizontal marca a temperatura em graus Celsius e o eixo vertical marca a pertinência. Na temperatura, há as marcas 25º, 50º e 75º. O eixo pertinência tem apenas uma marca com o número 1. Há uma linha inferior saindo da marca 25°, subindo em diagonal até a altura 1 e a marca de 50/ no eixo horizontal. A partir daí ela desce verticalmente até zero na marca 75°. Uma outra linha sai do ponto 1 do eixo vertical, segue reta até a marca 25° do eixo horizontal. A partir daí ela decresce até o ponto 0 na marca 50°, depois cresce até o ponto 1 na marca 75° e segue reta na marca 1. Em marca de temperatura há um vale e uma cume das variações das linhas e eles estão ligados por uma linha pontilhada.
Neste âmbito, Tanscheit (2004, p. 4) aponta que é possível classificar os valores de uma variável em um a função de pertinência com base nos termos:
» Clique nas setas ou arraste para visualizar as imagens
Admitindo a pertinência dessas hipóteses, Silva (2010, p. 44) observa que é necessária uma abordagem para avaliar regras que constituem as características das variáveis – denominado de Inferência fuzzy; que “permite tirar conclusões (deduzir, concluir) partindo de fatos conhecidos (Min-Max) e as variáveis linguísticas, de entrada e saída, representam o conhecimento em inferência fuzzy”.
Nota-se que o advento tecnológico permitiu que os dados dos usuários – os jogadores – fossem coletados em tempo real, de múltiplas formas e em contextos específicos. Assim, conceitos como o aprendizado de máquina e redes neurais passaram a ser um campo não apenas conceitual, mas uma abordagem implementada em diferentes áreas, com contextos distintos. A fragmentação da cultura digital é um fator favorável para a disseminação dos dados, de forma que a análise computacional coleta informações da melhor maneira possível e em qualquer lugar da rede. Milhares de dados são processados e analisados diariamente na web, em aplicações, mídias sociais e outras tecnologias modernas para prever cenários e acionar gatilhos para eventos distintos (KOTER e KELLER, 2019).
Dessa forma, consideram-se os dados como um elemento intrínseco na modelagem de soluções para o treinamento de uma máquina, um paradigma no processo de análise, de modo que as diversas fontes de dados – aplicações, mídias sociais, websites, jogos, etc. – possam ser expressas como um recurso para análise de detecção de padrões no conjunto de dados coletados pela máquina (LUGER,2015). Por ora, focaremos no aprendizado de máquina como um subcampo da IA, que descreve os instrumentos para compreender uma estrutura de dados e, em seguida, fornecer subsídios para modelar soluções que possam ser disponibilizadas para a tomada de decisões. Em síntese, de acordo com Mccuskey (2007) e Zhang et al. (2016), o aprendizado de máquina estuda métodos e abstrações para construir algoritmos que podem aprender utilizando recursos, parâmetros, diretrizes, características, propriedades e qualquer elemento que possa classificar determinado dado ou conjunto de dados de acordo com suas características. Noutros termos, a máquina deve saber o que procurar.
Embora o advento tecnológico tenha reorientado a práxis social, além de compor uma era de injunção tecnológica que, à primeira vista, foi capaz de operar na complexidade da existência subjetiva do homem; verifica-se que as máquinas ainda estão longe de pensarem ou assumir o protagonismo da sua existência. Dessa forma, campos e subcampos como IA e aprendizado de máquina buscam por métodos para que entidades artificiais possam aperfeiçoar automaticamente suas diretrizes com base nas experiências.
Portanto, se observamos autores em períodos diferentes da injunção tecnológica, como Holland (1975) e Luger (2015), é possível notar que ambos trabalharam com a premissa de que os métodos da AI são tentativas de reproduzir artificialmente o processo que define os seres humanos: a capacidade de pensar logicamente. Partindo dessas premissas, Bueno (2018, p. 20), defende que “os algoritmos de aprendizagem de máquina usam métodos computacionais para aprender informações diretamente dos dados sem depender de uma equação predeterminada”, buscando implementar o conceito da adaptabilidade para, por exemplo, compor suas diretrizes à medida que coletam e analisam amostras com base em um processo de aprendizagem.
Admitindo a pertinência dessas hipóteses, Shalev-Scwartz e Ben-David (2014) sugerem de maneira bastante clara que o aprendizado de máquina trabalha com o conceito de análise dos dados. Sendo assim, conforme demonstrado na Figura 3, os dois principais métodos para compor a dimensão do aprendizado são: aprendizado supervisionado e não supervisionado. Por hora, discutiremos as vertentes da aprendizagem supervisionada e, em tópicos subsequentes, os conceitos do método não supervisionado.
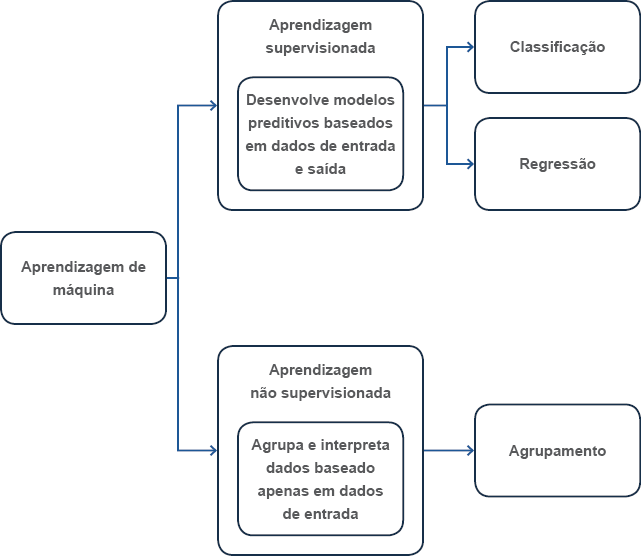
#PraCegoVer : A figura 3 demonstra, em um diagrama de blocos, as dimensões que compõem o aprendizado de máquina. Assim, o primeiro bloco à esquerda representa o Aprendizado de máquina. Ele se desdobra em duas vertentes, sinalizadas por setas azuis apontando para dois outros blocos. No bloco superior há a Aprendizagem Supervisionada e abaixo dela há o texto: desenvolve modelos preditivos baseados em dados de entrada e saída. Deste bloco saem duas setas azuis apontando para os blocos: classificação, acima e regressão, abaixo. No bloco abaixo de aprendizagem supervisionada, há o bloco Aprendizagem não supervisionada, em que há o texto: agrupa e interpreta dados baseado apenas em dados de entrada. Saindo deste bloco, há uma seta azul apontando para o bloco agrupamento.
De acordo com Luger (2015), a aprendizagem supervisionada é um conceito que trabalha usando dados (ou conjunto de dados) rotulados para treinar uma máquina; de forma que além dos dados de entrada, é necessário informar os resultados esperados. Observe, portanto, que a dimensão supervisionada usa os conceitos de IA para alimentar as entradas com dados e, em seguida, iniciar o processo de análise com base nos parâmetros que compõem os resultados esperados.
Esmiuçando um pouco mais, Faceli et al. (2011) nos lembra que se o resultado expresso pelos algoritmos IA forem incompatíveis com os resultados fornecidos, a IA deve automaticamente corrigir os seus cálculos em um processo cíclico que, possivelmente, é repetido inúmeras vezes de acordo com a quantidade de erros calculados pelos algoritmos, conforme figura 4.
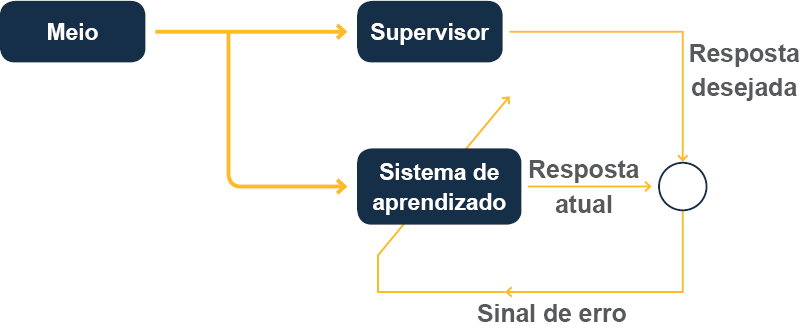
#PraCegoVer : A figura representa um esquema por setas. No início há um bloco com a palavra meio. Deste bloco saem duas setas que se bifurcam paralelamente. A primeira aponta para um bloco com a palavra supervisor. A segunda aponta para um bloco abaixo com a expressão sistema de aprendizado. Do bloco supervisor sai uma linha reta, que executa um ângulo de 90º, descendo, e aponta para um círculo. Do lado direito desta linha está a expressão resposta desejada. Abaixo do círculo, sai uma nova linha na mesma direção da resposta desejada, executa um ângulo de 90º e segue para a esquerda há uma pequena seta no meio desta linha, apontando para a esquerda, sob a qual está escrito sinal de erro. A linha sobe e atravessa o bloco sistema de aprendizado, finalizando com uma seta. Do bloco sinal de aprendizado sai mais uma linha com uma seta apontando para o círculo, na qual está escrito Resposta atual.
Observe, portanto, que a máquina é treinada identificando padrões com base no conjunto de dados de entrada e respostas conhecidas sobre determinado contexto; em seguida, a experiência adquirida – processo de aprendizagem – é utilizada para compor um modelo que servirá de base para realizar previsões com base em novas entradas – dados e respostas, conforme demonstra a Figura 5 (LUGER, 2015; BUENO, 2018).

#PraCegoVer : A figura demonstra um esquema por setas. À esquerda há as expressões entradas conhecidas e abaixo respostas conhecidas de cada uma dela sai uma seta, ambas apontando para a palavra Modelo. À direita há a palavra modelo e abaixo entradas novas. De ambas saem setas apontando para a expressão respostas preditas.
Nesse sentido, Bueno (2018, p. 20) evidencia que o “objetivo da aprendizagem supervisionada é construir um modelo que faça previsões baseadas em evidências na presença de incerteza. Usando essa técnica, um programa de computador pode ‘aprender’ a partir de observações". Além disso, o algoritmo de aprendizagem supervisionada aprende com base na quantidade de observações realizadas, sendo capaz de escolher os recursos necessários para analisar os dados e chegar a um resultado próximo do esperado; otimizando o seu desempenho preditivo, pois com base em experiência anteriores, por exemplo, com a análise e identificação de uma entidade específica – como identificar um indivíduo em uma foto, em meio a objetos e animais –, a máquina é capaz de reconfigurar seus parâmetros para analisar problemas semelhantes e reconhecer outras entidades, como objetos específicos.
» Clique nas abas para saber mais sobre o assunto
Um ramo da ciência moderna relacionado ao estudo e desenvolvimento de formas artificiais que se adaptem ao meio e exerçam funções semelhantes aos humanos.
Um subcampo da inteligência artificial que estuda formas para implementar modelos com base no reconhecimento de padrões; assim, a partir da análise de dados, é possível treinar dispositivos artificiais para imitar o comportamento humano na tomada de decisão.
Pode ser descrito como um modelo matemático, desenvolvido e implementado à imagem e semelhança do sistema nervoso central; assim como o cérebro humano, é possível treinar uma rede neural para resolver problemas complexos e auxiliar na tomada de decisões.
Ainda na década de 1950, o cientista da computação Arthur Samuel foi um dos pioneiros no estudo e implementação de algoritmos de IA, desenvolvendo um programa que simula uma partida de jogo de damas. O trabalho de Arthur Samuel forneceu subsídios para o projeto do psicólogo americano Frank Rosenblatt, denominado de perceptron, um projeto de rede neural artificial de 1957. Pelas limitações técnicas da época, o projeto de Frank Rosenblatt foi desenvolvido como um dispositivo físico, em vez do seu desejo inicial, como uma aplicação a ser implementada em diferentes contextos. É válido mencionar que embora o projeto perceptron tenha sido implementado usando o dispositivo da IBM – computador 704 –, o programa demandava um processo que dependia de um hardware específico.
Dessa forma, com as futuras implementações da equipe do projeto, o perceptron foi subsequentemente aprimorado, chegando ao mark 1 perceptron. Em síntese, o dispositivo idealizado por Frank Rosenblatt buscava mapear as entradas de dados, um vetor de valor real, para um valor binário simples. Idealmente, a aplicação era projetada para compor futuras soluções que tivessem a capacidade de reconhecer padrões no âmbito visual. De acordo com Luger (2015), o algoritmo do Perceptron de Frank Rosenblatt foi uma das primeiras iniciativas a utilizar a teoria hebbiana para compor uma solução baseada no sistema sensorial humano, sendo a forma mais básica de rede neural projetada para um neurocomputador, usando um classificador linear. De acordo com Furtado (2019):
Uma das primeiras e mais simples formas de RNA´s foram os perceptrons. Em um perceptron, os neurônios estão dispostos em várias camadas, que podem ser classificadas em camadas de entrada, onde os padrões são apresentados à rede; camadas ocultas, escondidas ou intermediárias, onde é feita a maior parte do processamento; e a camada de saída, onde a conclusão do processamento é apresentada (FURTADO, 2019, p. 11).
O perceptron é um tipo de rede neural que utiliza da modelagem matemática para compor um modelo baseado na percepção do sistema sensorial humano. Idealmente, conforme descrito pelo psicólogo Rosenblatt, o perceptron trabalha com três elementos distintos: sensores, elementos associativos e elementos reativos (LUGER, 2015; FURTADO, 2019). O sensor simula a capacidade de receber os estímulos do meio externos (entradas), conectadas a vários sensores que representam as conexões dos neurônios, resultando em diferentes saídas, conforme demonstra a Figura 6.

#PraCegoVer : A figura 6 demonstra um esquema de representação da arquitetura de uma rede Neural Artificial de múltiplas camadas. À esquerda há a palavra entradas. Logo depois há quatro pequenas esferas cinza enfileiradas em coluna, no centro três esferas cinza maiores enfileiradas em coluna e à direita há duas esferas cinza, do mesmo tamanho das anteriores, enfileiradas em coluna. Entre as esferas menores à direita e as centrais há linhas ligando todas elas. No alto, acima do esquema de linhas, há a palavra pesos. Abaixo das esferas centrais há a expressão neurônios intermediários e acima das esferas da direita há a expressão neurônios de saída. De cada uma das esferas da direita sai uma seta azul. À direita da imagem, entre as duas setas, há a palavra saídas.
Em termos de aprendizado de máquina, podemos definir a árvore de decisão como um dos principais métodos de classificação e regressão a compor as vertentes dos algoritmos de IA. Idealmente, as árvores de decisão são utilizadas de maneira abrangente no cotidiano da sociedade, sem a necessidade de algoritmos e métodos complexos de IA. Por exemplo, a estrutura de uma árvore denota uma arquitetura visual contendo determinadas instruções, baseadas em condições para possibilitar uma transição entre estados (LUGER, 2015). Em outras palavras, a árvore de decisão é uma representação visual de um processo que busca classificar uma determinada situação usando expressões em linguagem natural, conforme exemplo da Figura 7.
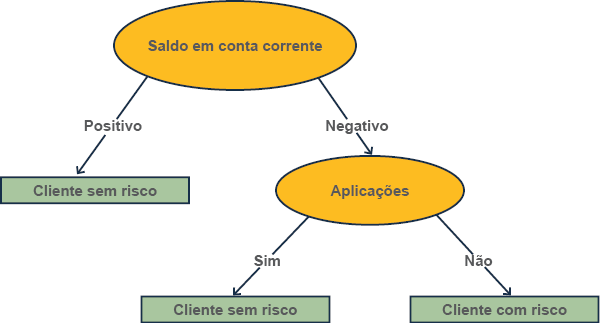
#PraCegoVer : A figura representa um diagrama mostrando uma árvore de decisão. Acima está a expressão Saldo em conta corrente, que está circulada. Dela saem duas setas: à esquerda uma seta com a palavra positivo, e à direita uma seta com a palavra negativo. Abaixo da seta positivo há um retângulo com a expressão Cliente sem risco. Abaixo da seta negativo, há um círculo com a palavra aplicações. Abaixo de aplicações saem duas setas: à esquerda a seta sim, sob a qual há um retângulo com a palavra cliente sem risco e à direita a palavra não, com a seta cliente com risco.
Se observarmos a atual conjuntura da transformação digital, à primeira vista, é possível afirmar que os dados rotulados são uma das principais fontes a compor métodos de treinamento para o aprendizado de máquina. No entanto, conforme aponta Luger (2015), ainda existem diferentes conjuntos de dados não rotulados que podem ser úteis para compor as vertentes do treinamento de uma IA. Idealmente, os dados não estruturados trabalham com um grau de incerteza, permitindo que a máquina classifique os dados coletados de forma lógica, sem depender das entradas respostas previamente conhecidas, conforme a aprendizagem supervisionada (Figura 8).

#PraCegoVer : Trata-se de um esquema por setas e blocos. À esquerda há um bloco com a palavra meio. Dele sai uma grande seta, sobre a qual está escrito “vetor descrevendo o estado do meio”, que aponta para outro bloco em que está escrito sistema de aprendizado.
Atualmente, diferentes sistemas utilizam da abordagem não supervisionada, como os sistemas de recomendação em e-commerce, plataformas de streamings, websites, aplicativos, e assim por diante. Basicamente, nos exemplos citados anteriormente o algoritmo trabalha analisando padrões com base no comportamento do usuário, como assistir determinado filme ou vídeo, comentar ou curtir uma foto, procurar um item em um buscador, clicar em links na web, classificar um produto etc.
O K-means (ou clustering K-means) é uma abordagem que opera no âmbito da aprendizagem não supervisionada. Dessa forma, o algoritmo K-means é um método em que é possível classificar um conjunto de dados sem rótulos, buscando padrões em dados subjacentes (LUGER, 2015). Ou seja, o algoritmo k-means – em que K, significa o número de clusters – é uma abordagem de análise de agrupamento, cujo objetivo é observar e dividir um determinado espaço vetorial conhecido em um número predeterminado de clusters.
Para Rodrigues (2012, p. 35), “a partir do algoritmo k-means é possível clusterizar dados em um espaço com
d
dimensões e ainda utilizar características como forma de discriminar o objeto analisado, desde que essas possam ser mapeadas para valores numéricos”. Observe, portanto, que o algoritmo K-means é um procedimento dinâmico e interativo, no qual se pode elencar as seguintes etapas para sua implementação:

Experimente montar uma breve narrativa sobre um jogo eletrônico do gênero RTS ( Real-Time Strategy ), que simula o confronto entre jogadores. Em seguida, utilizando os conceitos da lógica fuzzy, busque compor uma função para calcular possíveis ataques com base na dificuldade de terrenos distintos e eventos adversos – como relevo, chuvas, fortes ventanias, florestas, desertos, gelo, pântanos, e assim por diante. Dessa forma, a IA deve tomar uma decisão utilizado diferentes graus de pertinência. Para tanto, é necessário dividir o conjunto [0,1] em intervalos, e compor os graus de pertinência.
Enquanto o aprendizado supervisionado e não supervisionado busca analisar informações, padrões e outras estruturas baseadas em dados ou no próprio comportamento dos usuários, o aprendizado por reforço, por sua vez, é uma vertente da aprendizagem supervisionada, embora o "treinador" seja um ambiente real ou virtual. Neste âmbito, o papel do treinador – ou professor – é desempenhado pelo ambiente, em que a máquina – chamada de agente – não possui informações preliminares sobre o contexto a ser observado, mas tem a capacidade de interagir com o ambiente, conforme demonstra a Figura 9.
Dessa forma, a aprendizagem por reforço é eficaz para lidar com situações que não dependem da observação de dados, mas de uma interação que compõe um sistema baseado no feedback entre entidades – agente e ambiente (LUGER, 2015). Assim, é possível aplicar o conceito da aprendizagem por reforço em, por exemplo:

#PraCegoVer : A figura demonstra um esquema de decisão por setas e blocos. Há um bloco com a palavra meio. Dele saem duas setas cinzas grandes que se bifurcam paralelamente sobre as quais está escrito vetor de entrada. Elas apontam para os blocos críticos acima e Sistema de aprendizagem abaixo. Além disso, sai uma terceira seta na forma de uma linha preta que se liga ao bloco crítico e ao lado da qual há a expressão reforço primário. Entre o bloco Crítico e Sistema de Aprendizado há uma nova seta preta com a expressão heurística de reforço. Do bloco sistema de aprendizado sai uma nova seta cinza grande, que dá a volta na imagem e se liga ao bloco meio, do início. Do lado direito desta seta está a palavra ações.
No âmbito da aprendizagem de máquina, temos o algoritmo Q-learning como uma solução para trabalhar no contexto do aprendizado por reforço. Dessa forma, enquanto o agente interage com o ambiente, através da execução de ações, o algoritmo busca analisar o contexto (estado atual) para encontrar a melhor ação a ser executada (LUGER, 2015). É válido mencionar que a letra “Q” em Q-learning é atribuída a
quality
(qualidade). A qualidade, neste contexto, representa o quão útil uma ação pode ser executada para obter determinado resultado (COPPIN, 2010).
De acordo com Pessoa (2011, p. 24), “o mecanismo de aprendizagem Q-Learning foi descrito inicialmente em 1989 por Watkins da universidade de Cambridge, na sua tese de doutoramento”. Dessa forma, podemos definir o mecanismo de aprendizagem baseado no pseudo-código do Q-Learning proposto por Watkins (1989):
Em que:
» Clique nas abas para saber mais sobre o assunto
Variável que representa o estado anterior, antes da ação.
Representa a ação anterior do sistema, para um contexto distinto.
Representa o algoritmo Q-learning.
Variável que representa o estado atual do sistema.
É a taxa de aprendizado do sistema, em que o algoritmo Q-learning é representado por um valor entre 0 e 1, em que se o valor tende a 0, dificilmente o aprendizado pode ocorrer; ou, caso o valor tenda a 1, o processo de aprendizado ocorre rapidamente.
Atributo que opera modelando a relação entre as ações e as recompensas imediatas ou futuras (LUGER, 2015).
Com base nos conhecimentos sobre a inteligência artificial e suas principais vertentes, projete um jogo de tabuleiro (Xadrez ou Jogo da Velha) que demonstre o comportamento da aprendizagem supervisionada, não supervisionada ou por reforço. Não se esqueça de implementar uma árvore de decisão para auxiliar no projeto.
Atualmente, a inteligência artificial é uma das principais abordagens implementadas na indústria dos jogos eletrônicos; seja pela sua dimensão multifacetada, multidimensional ou mesmo pela dinâmica que compõe a subjetividade do desenvolvimento de um processo lúdico. Idealmente, deseja-se crer que a injunção tecnológica permitirá que abordagens como o aprendizado de máquina possa modelar o comportamento de agentes inteligentes, indo além da interação e feedback, que compõem os atuais algoritmos de IA. Além disso, conforme discutimos ao longo da unidade, conceitos fundamentais da lógica fuzzy e aprendizado de máquina permitem implementar métodos para analisar dados com base no comportamento dos jogadores e, em seguida, conduzir uma análise detalhada para modelar soluções inovadoras com diferentes graus de pertinência.

Título:
Fundamentos da Inteligência Artificial
Autor:
João Luís Garcia Rosa
Editora:
LTC
Ano:
2011
Comentário:
leia o Capítulo 3, que ampliará o entendimento sobre os principais conceitos que compõem a lógica de predicados, uma das bases para compor algoritmos de Inteligência Artificial (IA), bem como estratégias de busca para sistemas de produções IA, busca em grafos, redes neurais e aprendizado de máquina.
Onde encontrar?
Biblioteca Virtual da Laureate