Nesta unidade, apresentaremos alguns conceitos básicos para, posteriormente, aprendermos o conteúdo sobre a área de Big Data . Nesse sentido, apresentaremos o perfil do profissional de Big Data .
Em seguida, conheceremos os conceitos e os componentes da tecnologia Big Data , com explicações sobre o processo de Big Data e/ou Data Science .
Ainda, aprenderemos sobre o armazenamento de dados e a representação dos diferentes tipos de dados: texto, valor numérico, imagem e som.
Finalmente, conheceremos os conceitos sobre arquitetura e organização de computadores.


Iniciaremos este conteúdo destacando que os dados são gerados desde o horário em que uma pessoa sai de casa em direção ao trabalho até o número de passos que dá até uma loja, o que consumiu e em quanto tempo.
Contudo, é necessária uma análise adequada para que esses dados, um aglomerado de números, transformem-se em informação que possa ser utilizada no planejamento de organização. Note que, com base na localização, nas preferências do consumidor, na rotina e em outras informações disponíveis, uma empresa pode estimar tendências e fazer previsões que, efetivamente, determinam um melhor rumo nos negócios dessa empresa.
Além disso, na área da saúde, sintomas parecidos em pacientes de uma mesma região podem servir como um alerta para que médicos identifiquem uma epidemia ou um surto que se aproxima. Sugestões de filmes e séries em serviços de streaming também usam a tecnologia, analisando dados de perfil e histórico de buscas para indicar o que o usuário gostaria de assistir dentre os títulos disponíveis.
No dia a dia de trabalho, as mudanças têm sido visíveis. Por isso, refletir sobre a quantidade de registros que é gerada sobre o que produzimos, pensamos, sentimos ou até mesmo desejamos é muito importante.
Por conta de tudo isso, técnicas têm sido desenvolvidas para possibilitar o processamento de dados com alto desempenho e disponibilidade. Nesse sentido, o Big Data visa simplificar a coleta, o processamento e a visualização de informações, oferecendo uma padronização eficaz. Assim, as empresas conseguem detectar e compreender tendências em tempo real e, por consequência, refinar os seus produtos e torná-los mais lucrativos.
É importante ressaltar que as soluções de Big Data trabalham os dados “brutos” até que estes sejam transformados em ideias (em inglês, insights ) valiosas para uma sabedoria que permitirá uma tomada de decisão efetiva e eficiente. A figura a seguir procura demonstrar a complexidade dessa transformação:
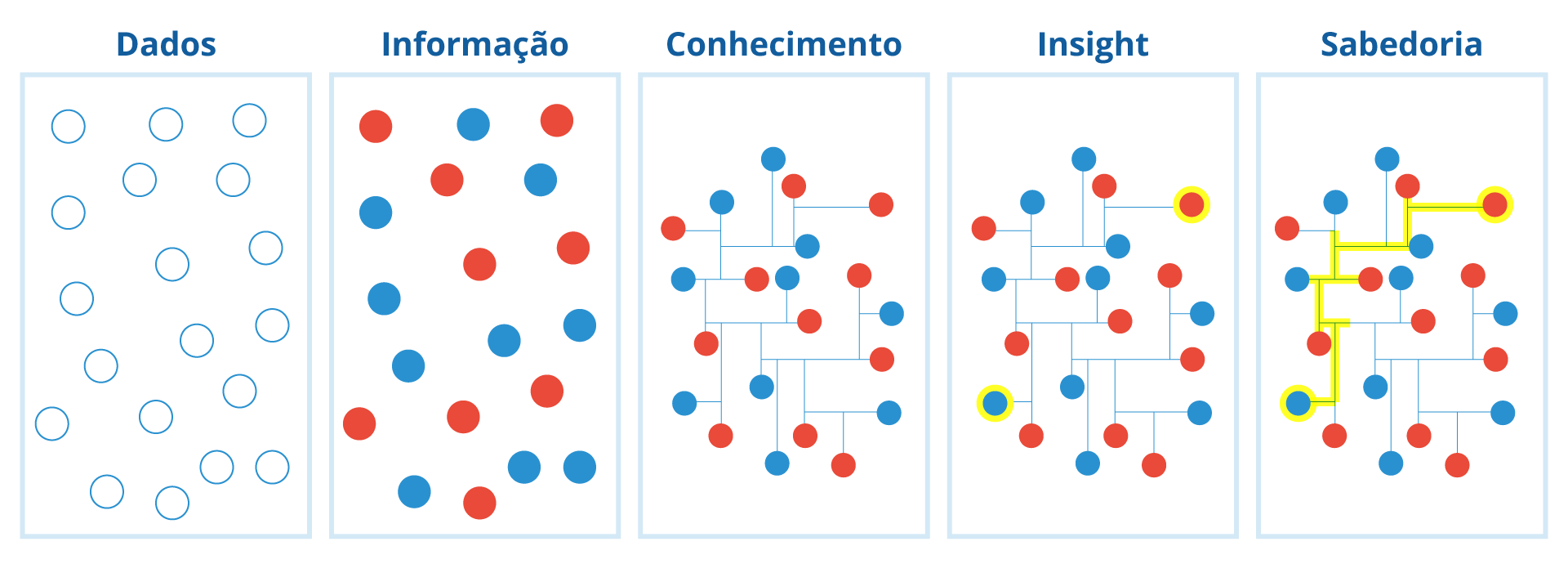
Na Figura 1.1, podemos notar que os dados brutos constituem a matéria-prima da informação , ou seja, é a informação não tratada de uma organização. A informação é o conjunto de dados que foram processados, seja por meio eletrônico, mecânico ou manual, e que produziu um resultado com significado. As informações são valiosas, mas o conhecimento constitui o saber, pois produz ideias e experiências que as informações não são capazes de representar. Se informação é dado trabalhado, então o conhecimento é a informação trabalhada. Já o conhecimento transforma-se em sabedoria quando se torna necessária uma tomada de decisão assertiva no contexto de negócio da organização.
A Ciência de Dados (ou Data Science , em inglês) surge para sanar a necessidade por novas aplicações, permitindo que novas indústrias utilizem, de forma criteriosa, grandes quantidades de dados. Exemplos de aplicações incluem reconhecimento de fala, reconhecimento de objetos em visão computacional, robôs e carros autônomos, bioinformática, neurociência, a descoberta de exoplanetas e uma compreensão das origens do universo e até mesmo a montagem de times de beisebol baratos, mas vencedores. Em cada um dos casos citados anteriormente, deve-se combinar o conhecimento da área de aplicação com o conhecimento estatístico e implementar tal combinação, buscando utilizar as últimas novidades da ciência da computação, conforme apresentado na Figura 1.2.
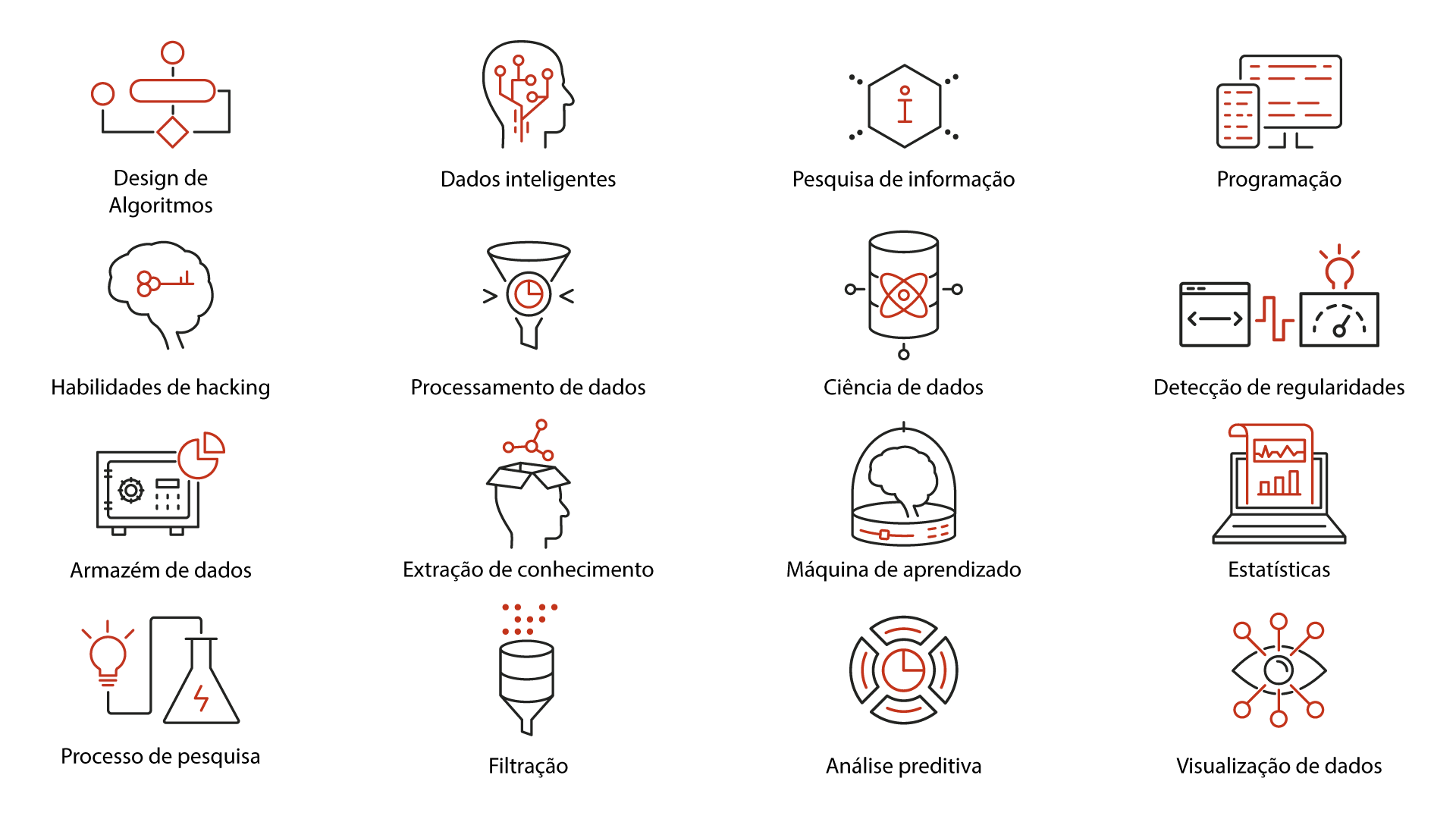
O cientista de dados deve ter a habilidade de trabalhar de forma adequada com os dados, gerando informações pertinentes e identificando padrões de comportamento. Portanto, algumas competências e habilidades são necessárias:
Nesse sentido, podemos notar que todas as competências citadas, associadas à Inteligência Artificial e baseadas na premissa de que sistemas podem aprender com dados, identificam padrões e tomam decisões com cada vez menos intervenção humana. Portanto, os profissionais da Ciência de Dados devem entender tanto de ferramentas quanto dos processos disponíveis.
Além disso, todo cientista de dados deve procurar compreender a área de negócio na qual irá atuar. Cada área de negócio tem as suas particularidades, e deve haver uma compreensão ampla dessa área. Para permitir um trabalho que gere valor, o cientista de dados deve questionar a organização:
O cientista de dados vai utilizar o Big Data como matéria-prima, aplicando diversas técnicas e colhendo insights . Mas a responsabilidade por coletar e armazenar os dados, normalmente, é do engenheiro de dados . Esse profissional utiliza conhecimento em ciência da computação para criar sistemas e resolver problemas de processamento de dados em tempo real, manipulando quantidades imensas de dados para o Big Data .
Mais especificamente, o engenheiro de dados é responsável pela criação do pipeline , que transforma os dados brutos que estão nos mais variados formatos, desde bancos de dados transacionais até arquivos de texto, em um formato que permita ao cientista de dados começar seu trabalho. O engenheiro de dados deve, portanto, ter habilidades e competências para arquitetar sistemas distribuídos, além de criar pipelines confiáveis, combinar fontes de dados, criar a arquitetura de soluções e, obviamente, colaborar com a equipe de Ciência de Dados para construir as soluções certas para essa equipe.
O trabalho do engenheiro de dados é tão importante quanto o trabalho do cientista de dados, mas aqueles costumam ter menor visibilidade, uma vez que estes estão mais distantes do produto final que resulta do processo de análise, o que é produzido pelo cientista de dados.
Outro profissional importante é o arquiteto de dados .
A qualidade de uma imagem depende, basicamente:
O ponto de partida para a compreensão dos próximos conceitos é ter em mente que o Big Data trata-se do processamento de um grande volume de dados, dados esses que, via de regra, não poderiam ser processados via mecanismos habituais, como por meio de um Sistema Gerenciador de Banco de Dados (SGBD).
Esse processamento inicia-se a partir da captação de dados de fontes diversas, sejam elas internas (da própria organização que está estruturando o processamento) ou externa. Não raro, os dados captados para início do processamento estão em sua forma bruta, ou seja, não estão estruturados e precisam ainda passar por etapas de tratamento para que sejam utilizados.
Os dados citados anteriormente podem ser divididos em algumas categorias:
São aqueles dados cuja estrutura está definida e, geralmente, são obtidos de um banco de dados próprio ou cedido.
São aqueles que não seguem propriamente uma estrutura definida (e em geral são obtidos tanto interna quanto externamente à organização que está realizando o processo de Big Data ).
São dados gerais, incluindo imagens, vídeos, PDFs e outros arquivos diversos.
Para o tratamento, o gerenciamento, o tráfego e a manipulação de uma grande massa de dados, é necessário, ao engenheiro de Big Data , pensar conceitualmente na estrutura que irá suportar tal quantidade de recursos, atentando-se sempre à disponibilidade do conteúdo e ao consumo de hardware e escalabilidade dessa estrutura.
Quanto aos critérios de disponibilidade, podemos usar como exemplo o uso de containers para ativar serviços em poucos minutos.
Nesse contexto, containers são imagens de um sistema completo (incluindo, às vezes, até mesmo um Sistema Operacional). Essas imagens contêm todas as informações e configurações de um sistema, de forma que, em caso de pane em algum servidor que hospede uma determinada aplicação, o container com a imagem cópia é iniciado, e o serviço retorna à atividade em questão de minutos.
Vejamos a definição de containers , de acordo com o site oficial da distribuição Linux:
Um container Linux® é um conjunto de um ou mais processos organizados isoladamente do sistema. Todos os arquivos necessários à execução de tais processos são fornecidos por uma imagem distinta. Na prática, os containers Linux são portáteis e consistentes durante toda a migração entre os ambientes de desenvolvimento, teste e produção. Essas características os tornam uma opção muito mais rápida do que os pipelines de desenvolvimento, que dependem da replicação dos ambientes de teste tradicionais (O QUE É…, 2019, on-line).
A Computação em Nuvem (ou Cloud Computing ) também é um elemento amplamente utilizado quando tratamos do tema Big Data . Ao contrário do que, erroneamente, se pensa, a computação em nuvem tem uma estrutura física para armazenamento de arquivos. Os arquivos não ficam propriamente “em nuvem”, uma vez que eles estão fisicamente em algum local. O que caracteriza o termo “nuvem” é a possibilidade de executar aplicações sem que estas estejam instaladas no computador do usuário que as requer.
São exemplos de serviço de nuvem o Google Drive (Google) e o OneDrive (Microsoft). Tais exemplos citados apresentam uma gama de aplicações (editor de textos, planilha eletrônica, ferramenta para criação de gráficos e vetores) totalmente on-line , dispensando a instalação de software em seu computador.
Esse mesmo conceito é utilizado por empresas quanto ao uso de aplicações desktop . O uso da computação em nuvem provê baixo consumo de hardware (considerando que as aplicações não rodam localmente no requerente) e alta disponibilidade, devido ao fato de estarem na nuvem , possibilitando o acesso a partir de qualquer máquina previamente conectada à internet. Ressalta-se, portanto, a necessidade de disponibilidade do conteúdo, por meio de uma estrutura escalável e pensada quanto à disponibilidade.
Geralmente, sistemas de computação em nuvem estão diretamente atrelados a um alto processamento, seja este um processamento paralelo ou distribuído . Este tipo de processamento possibilita que uma mesma carga de tarefas em uma máquina (podemos considerar um servidor para nossos exemplos de Big Data) seja distribuída entre vários outros servidores de maneira inteligente e escalonar; assim, quanto maior for o tráfego, maior será a divisão dos processos por máquina.
É intuitivo pensar que, com esses critérios, uma estrutura de redes de alta performance é requerida, para suportar o alto tráfego de informação sem apresentar oscilações. Toda essa gama de recursos, geralmente, é utilizada em conjunto, para prover ambientes de Big Data eficientes. Afinal, vivemos na era da informação, e as informações crescem em um ritmo frenético nos dias atuais.
Com o advento das Inteligências Artificiais, da Internet das Coisas ( IoT ) e de outros aparatos tecnológicos conectados à grande rede, o crescimento do volume de informações torna-se exponencial.
Ao tratarmos de Big Data , destacamos diretamente alguns critérios:
O que é Big Data ? O site da Oracle apresenta com mais detalhe a definição de Big Data , explicando sobre os 5 Vs (volume, velocidade, variedade, valor e veracidade), sintetizando a história do Big Data e apresentando Casos de Uso.
Sistemas de Big Data diferenciam-se de sistemas de Business Intelligence (BI):
É bastante comum, ao ingressarmos no ambiente Big Data , confundir seus recursos e até aplicabilidades com sistemas de Business Intelligence (BI). Sistemas de BI, geralmente, armazenam informação de Data Warehouse , que podem ser considerados grandes armazéns de dados utilizados por empresas para gerar tomada de decisões baseada em cenários internos, ou seja, da própria empresa.
De contrapartida, sistemas de Big Data utilizam dados gerais, muitas vezes externos à empresa, como já citado anteriormente. É bastante comum, inclusive, que empresas de grande porte utilizem sistemas de Big Data para gerarem dados a serem armazenados em seu Data Warehouse próprio, para fins de utilizar tais dados, posteriormente, em estruturas de BI da organização.
O armazenamento de dados obtidos por Big Data passa por um processo de tratamento conhecido por ETL ( Extract, Transform, Load ). Vejamos, a seguir, mais detalhes:
Esse processo consiste em obter os dados das mais diversas fontes (dados estruturados, semiestruturados e não estruturados). Para a obtenção desses dados, realiza-se o processo de extração, que capta, sem distinção, os dados mais diversos, conforme alguns critérios pré-selecionados.
O processo de transformação é responsável por tratar, previamente, os dados, adequando-os ao perfil que a organização deseja utilizar. Um dos itens mais importantes nessa etapa é a categorização dos dados por meio de categorias de dados, chamadas também de Data Marts , que organizam os dados, deixando-os prontos para a próxima etapa.
A etapa de carregamento utiliza os Data Marts para popular uma estrutura ou algum sistema que processe os dados, transformando-os em informação. Geralmente, utiliza-se um banco de dados (relacional ou não relacional) ou sistemas de inteligência artificial que tomam decisões imediatas, mediante recepção dos dados.
Todo esse processo é bastante trabalhoso, porém grande parte desse trabalho pode ser extinguida com o uso de software ou framework de processamento de Big Data . Um dos frameworks mais conhecidos dessa categoria é o Hadoop.
O Hadoop é um framework de código aberto que permite que qualquer pessoa modifique e implemente novas funcionalidades, e é desenvolvido e mantido pela Apache Software Foundation . O Hadoop utiliza arquitetura clusterizada, ou seja, um conjunto de computadores que trabalham em conjunto, como se fossem apenas um.
Da mesma forma que existem unidades de medidas para representar distâncias (quilômetros, milhas, centímetros, metros), peso (quilos, toneladas, gramas) tempo (minutos, segundos, dias, horas), existem também as unidades de medida computacionais, que servem para mensurar pesos de dados, arquivos e qualquer informação que tenha cunho digital.
A menor unidade de armazenamento é o bit (
Binary Digit
), que pode assumir apenas dois valores: 0 (zero) ou 1 (um); por isso o nome binário. A base binária vem da área da eletrônica, em que o dígito zero representa um circuito desligado, enquanto que o dígito um representa um circuito ligado. Na computação, esses conceitos têm as representações apresentadas no Quadro 1.1, a seguir:
O conjunto de 8
bits
é responsável por formar 1
byte
. O cálculo das unidades de medida computacionais é feito da seguinte forma: dígitos binários elevados a cada 10 potências, tomando-se como partida a potência zero. Por haver uma representação de apenas duas opções, é comum chamarmos essa representação de “base 2”, pois a base do expoente é sempre o número dois. Vejamos o Quadro 1.2, a seguir:
Como já verificado, as unidades de medidas têm o bit como menor elemento na computação.
Uma sequência de bits é composta apenas de números 0 e números 1. Isso significa que qualquer dado, seja ele um texto, uma imagem, um vídeo, um cálculo ou mesmo um programa de computador, é lido e interpretado como uma sequência lógica de “zeros” e “ums”. Essa conversão é feita de maneira automática pela arquitetura lógica dos computadores, quando estes recebem algum tipo de dado.
A conversão de números decimais para binários, por exemplo, dá-se com a seguinte lógica:
Repete-se esse procedimento quantas vezes forem necessárias, até que o quociente seja o número um. Veja a Figura 1.3, a seguir, para facilitar a sua compreensão:
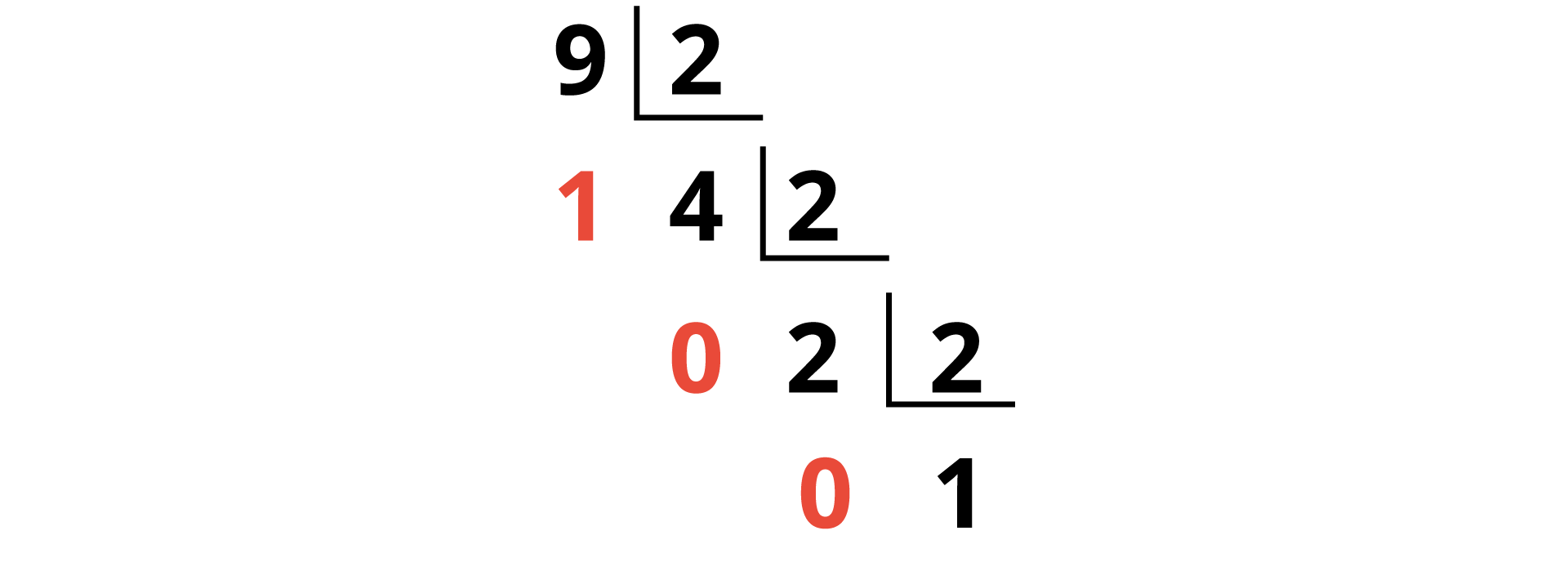
Podemos observar na Figura 1.3 que o processo de divisão foi repetido sequencialmente, até que o número 1 surgisse como quociente. A leitura do binário resultante dessa operação é: 1001. A leitura correta de qualquer binário gerado por esse método deve ser feita de baixo para cima. O número 9, especificamente, gera o mesmo resultado lendo-o de baixo para cima ou de cima para baixo, mas isso não ocorre com qualquer número. Veja na Figura 1.4, a seguir:
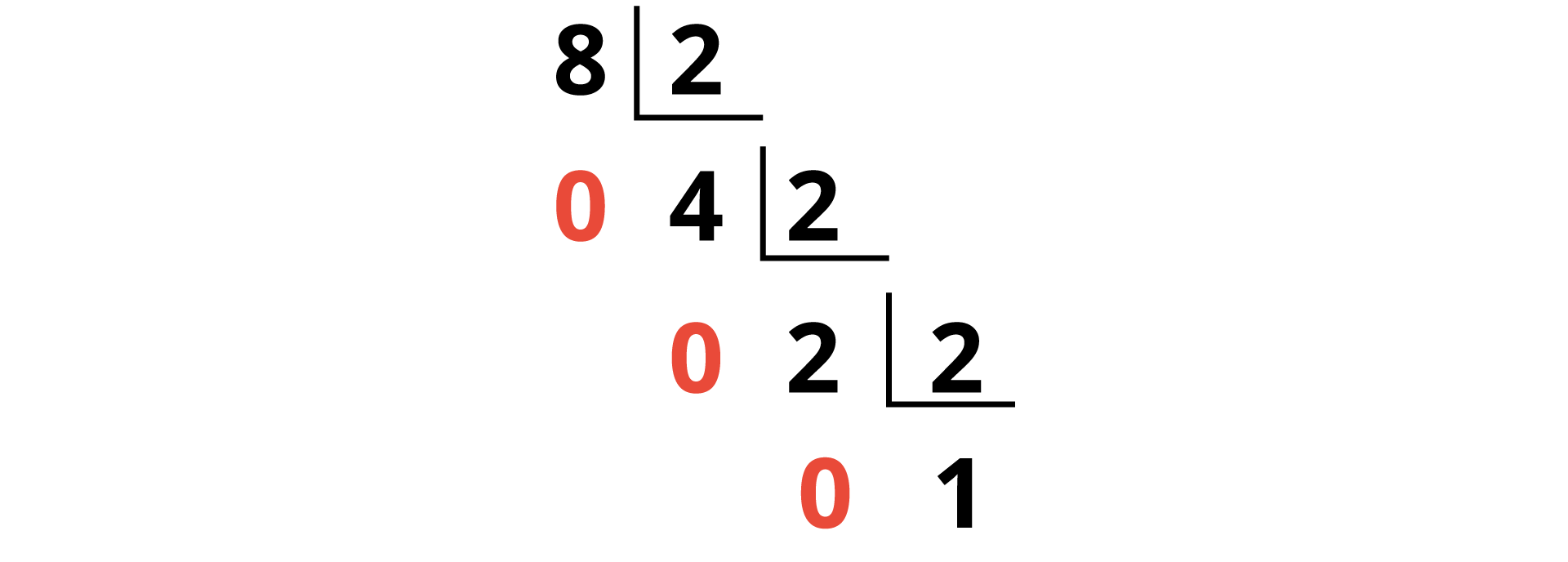
Conforme mostrado na Figura 4, o decimal 8 convertido em binários resulta em 1000 (bem diferente do resultado 0001, se fosse lido de cima para baixo).
Existem outros tipos de conversão, como textos, imagens e vídeos para binários. Essa estrutura de conversões é um pouco mais complexa e requer certa prática para ser executada. Conhecimentos sobre base 16 também serão bem-vindos. A base 16 tem como característica trabalhar com números de 0 a 15. Os numerais de 0 a 9 são representados pelos respectivos números; já os numerais de 10 a 15 são representados por letras de A a F.
Independentemente do tipo de dado, tudo é convertido em binários, para que seja possível a leitura correta por um computador. Isso não significa que, em sua estrutura digital, os dados possuam as mesmas características. Muito pelo contrário!
Uma imagem, por exemplo, terá uma representação binária, diferente das representações binárias de arquivos de vídeo, áudio, números ou texto.
Entretanto, essas representações não são as únicas diferenças entre os diferentes tipos de arquivos/dados. A própria estrutura de medição dos arquivos é distinta para cada categoria citada.
Imagens, por exemplo, têm as dimensões medidas em pixels . As medidas de cada pixel dependem, basicamente, da resolução trabalhada em uma imagem. Quanto maior a resolução, maior a quantidade de pixels , pois isso significa que para cada polegada existe um número maior de pixels , o que torna a imagem de alta qualidade. Dessa maneira, quando o termo “imagem de alta resolução” é expresso, significa o mesmo que dizer que uma determinada imagem tem mais pixels por polegada.
Um bom exemplo é comparar esses pixels como grãos de areia. Se os grãos estiverem dispersos, distanciados uns dos outros sobre um piso frio, será possível enxergar partes do piso sob eles. Todavia, se os grãos estiverem agrupados, o piso será menos visto e os grãos parecerão cada vez mais nítidos. Quanto mais próximos estiverem, maior será a nitidez e mais compactos parecerão, a ponto de se assemelharem a um único bloco de areia. Isso ocorre porque existem mais grãos por centímetro; ou, em uma alusão ao tema atual, existem mais pixels por polegada.
A mesma ideia se aplica a arquivos de áudio e vídeo; porém, quanto à qualidade de compressão e à quantidade de frames por segundo.
Outro exemplo que podemos apresentar é o de um elástico com algumas pedrinhas presas a ele (similar àqueles usados como bijouteria). As pedrinhas estão tão próximas umas às outras que parecem cobrir o elástico por completo; porém, se o elástico for esticado, pequenos vãos começarão a surgir entre uma pedrinha e outra, revelando partes do elásticos sob elas.
Essa mesma lógica ocorre com arquivos de áudio, que podem ter maior ou menor compressão. Os arquivos com maior compressão simbolizam o elástico esticado, ou seja, possuem pedaços visíveis do elástico entre as pedrinhas, resultando em uma baixa qualidade de áudio. Já os arquivos com menor compressão simbolizam o elástico esticado , que tem toda a sua estrutura coberta por pedrinhas, o que simboliza arquivos de maior qualidade de áudio.
Já quanto aos arquivos de vídeo, o fator determinante (além dos pixels por polegada) é a quantidade de frames (quadros) exibidos por segundo. Por padrão, um arquivo de vídeo possui 24 frames por segundo (FPS). Quanto mais frames por segundo, maior a qualidade obtida no vídeo.
Podemos imaginar o movimento de uma bola quicando sobre o chão. O vídeo armazena uma sequência de vários quadros que, ao serem executados rapidamente, simulam movimento. O espaçamento entre um quadro e outro, embora seja relativamente curto, pode tornar a qualidade do vídeo baixa. Quando a quantidade de quadros por segundo aumenta, diminui-se o espaçamento entre os quadros, dando a impressão de aumento na qualidade da imagem do vídeo.
Todos esses critérios de peso, qualidade e compressão devem ser analisados pelos sistemas de
Big Data
, pois, como uma grande gama de dados é lida, processada e armazenada simultaneamente, é necessário ter bom senso para que a plataforma de armazenamento não “infle” por estar com pouco material de alta qualidade, quando, na verdade, esperava-se ter muitos dados de qualidade mediana, por exemplo.
Os dados utilizados no Big Data podem ser de três tipos:
Podemos relacionar a arquitetura de computadores como um mapa para se caminhar do ponto A ao ponto B. Existirão diversas vias que poderão ser escolhidas. Da mesma maneira, existem várias formas de se realizar o deslocamento (a pé, de bicicleta, de carro, de ônibus etc., e isso irá depender do caminhos escolhidos e da localização dos pontos A e B).
Já na arquitetura e na organização de computadores, a lógica é a mesma: existe uma estrutura feita para realizar as tarefas da melhor forma possível; em contrapartida, existem os critérios de organização, que irão atuar sobre a arquitetura utilizando os recursos computacionais com total eficiência.
De acordo com Stallings (2002 , p. 6), a estrutura e a função dos componentes de um computador podem ser definidas como: “Estrutura: a forma como os componentes estão inter-relacionados. Função: a operação de cada componente individual como parte de uma estrutura.
Além dos dispositivos convencionais e amplamente conhecidos, como os hardwares (placa-mãe, placa de som, placa de vídeo, placa de rede, placa de memória etc.) divididos nas categorias “dispositivos de entrada” e “dispositivos de saída”, trataremos de um componente que é considerado o cérebro do computador: a CPU.
A sigla CPU significa Central Processing Unit (Unidade Central de Processamento). Ela é responsável por realizar todas as operações lógicas do computador, e é formada pelos seguintes componentes:
O Hadoop é um framework desenvolvido e mantido pela Apache Software Foundation . Sobre sua aplicação, é correto afirmar que:

Igor Zhirkov
Editora: Novatec
ISBN: 978-85-7522-667-4
Comentário: O livro é desenvolvido com assuntos mais detalhados sobre a arquitetura de computadores e o funcionamento dos sistemas de processamento interno, como alocação de memória de priorização de tarefas, e aborda a linguagem Assembly em plataforma com arquitetura Intel 64.
Nesta unidade estudamos os princípios básicos que envolvem a tecnologia Big Data e, além disso, conhecemos um pouco de suas características, sua aplicabilidade e sua estrutura. Nesse sentido, é importante nos aprofundarmos mais em todos os tópicos abordados.
Com isso, destacamos que o tema Big Data é extremamente amplo. Recomendamos que você tenha como princípio de estudos algum framework de código aberto, como o Hadoop, apresentando nesta unidade.
EVOLUÇÃO no processo de dados. Deviante , fev. 2018. Disponível em: < http://www.deviante.com.br/wp-content/uploads/2018/02/data-driven-01.jpg >. Acesso em: 17 abr. 2019.
O QUE É um container Linux? Redhat , 2019. Disponível em: < https://www.redhat.com/pt-br/topics/containers/whats-a-linux-container >. Acesso em: 30 mar. 2019.
STALLINGS, W. Arquitetura e Organização de Computadores: projeto para o desempenho. 8. ed. São Paulo: Pearson Practice Hall, 2010.