Segurança no Ambiente Web
Segurança no Ambiente Web


O que é informação?
Desde os primórdios da humanidade, houve a necessidade de se comunicar, ou por meio de desenho, de gestos, de sinais, de sons e tais elementos tinham o objetivo de indicar alguma informação ou até perpetuar um conhecimento importante para gerações posteriores. Atualmente, não é diferente, porém, a quantidade de dados produzidos é exponencial a cada ano. Logo, é essencial que ocorra um gerenciamento de tais dados e que eles estejam devidamente seguros, de acordo com o grau de sua importância.
Em decorrência dessa explosão de dados, surgiram diversas áreas como a Segurança da Informação, a Recuperação da Informação (há dados, mas como recuperá-los?), a Visualização de Informações (visualizar uma coleção enorme de dados por meio visuais auxilia na tomada de decisão), a Big Data (área responsável por gerir enormes quantidades de dados e obter informações não triviais) entre outras (SÊMOLA, 2014). Como o foco de nosso estudo é a Segurança da Informação começamos do básico até adentrar cada vez mais nessa área.
Bons estudos!
Na introdução apareceram alguns termos relacionados à comunicação, dentre os quais podemos destacar: “dado”, “informação” e “conhecimento”. Entretanto, ao tentar defini-los, a princípio, é possível que se gere certa confusão. Então, a seguir, descreveremos cada um deles indicando a hierarquia entre si, juntamente com o conceito de comunicação. Tais definições irão nos ajudar a compreender os termos nas próximas seções.

Ao nos referirmos o termo “dado”, indicamos que ele está sendo armazenado de alguma forma, porém, não há nenhum sentido para um ser humano e nem para um computador uma vez que o dado é apenas uma sequência de bits sem nenhum contexto (HINTZBERGEN et al ., 2018). É bem provável que para você, por exemplo, o dado 34435 não tenha nenhum sentido e não lhe seja útil.
Por outro lado, a “informação” é a contextualização de um dado, ou seja, é quando um conjunto de dados passa a ter sentido (HINTZBERGEN et al ., 2018). Por exemplo, imagine que você tenha recebido uma lista com 50 números com 11 dígitos cada. A priori, a lista não tem nenhuma lógica, mas depois de alguns minutos a pessoa que lhe entregou a lista lhe informa que a lista tem o título que ela havia se esquecido de colocar ao lhe entregar: “Relação de aprovados no vestibular por número de CPF”. Antes, você tinha um dado sem sentido, agora você tem uma informação relativa às pessoas aprovadas em um vestibular.
Em último nível temos o termo “conhecimento”. Ele está diretamente relacionado com diversas informações interconectadas de forma lógica. Em nosso exemplo anterior, podemos dizer que aquela lista de aprovados do vestibular é dos candidatos do Curso de Direito que obtiveram as melhores notas nos últimos dois anos. Observe que com um conjunto de informações conseguimos obter respostas mais elaboradas, pois cruzamos diversas informações para obter algo maior.
Tendo em mente esse conceito, nos deparamos com um grande problema, ou seja, a quantidade de dados, sua variedade e a velocidade com que crescem é sem dúvida um dos grandes desafios para a TI (Tecnologia da Informação). A EMC Corporation (hoje, DellEMC – empresa de armazenamento e segurança de dados.) Estimou que em 2020 haverá 44 zettabytes gerados no mundo. Imagine a complexidade que é gerenciar e armazenar ( datacenters ) tais dados e quanto é importante manter a sua segurança (MARQUESONE, 2016).

Em nível de comparação, se formos paralelizar esse número com o de pessoas existentes no planeta, que é de aproximadamente 7 bilhões, esse número saltaria para 1 trilhão de pessoas. Além disso, nem foram levados em consideração os dados produzidos por máquinas, a exemplo da área da Internet das Coisas ( Internet of Things – IoT), que pode ser um dado gerado por um sensor de movimento ativado em sua casa, o qual gera uma notificação que você recebe via software (MARQUESONE, 2016).
Em relação à variedade de dados, eles podem ser semi estruturados, não estruturados e estruturados. Dentro desse universo, o que mais nos interessa são os dados estruturados e dentre vários destacamos o banco de dados relacional. Para se ter uma noção da complexidade que é armazenar um dado, todos os SGBDs (Sistemas de Gerenciamento de Banco de Dados) devem garantir as propriedades ACID (MARQUESONE, 2016), acrônimo de Atomicidade, Consistência, Isolamento e Durabilidade. A seguir explicamos cada uma delas.
Garante que uma transação (conjunto de ações: inserção, alteração, exclusão) sejam todas efetuadas ou nenhuma delas. Por exemplo, numa transação de compra de ingresso, você efetuou o pagamento e, por consequência, um ingresso deveria estar disponível.

As tabelas de um banco de dados são interconectadas e devem garantir que as suas restrições de integridade sejam respeitadas.

É o ato de que uma transação não conheça outras transações, ou seja, uma transação não irá interferir em outra. Em uma compra on-line , pense na complexidade que seria ao tentarmos esperar a transação de outro cliente enquanto estivéssemos comprando. Com certeza, com essa abordagem ganhamos maior desempenho e mais agilidade.

É o ato de garantir que as transações ocorridas com sucesso tenham seus dados armazenados.

A Internet conecta todos nós em um espaço único, o ciberespaço ou rede mundial de computadores. Lá, trocamos informações entre diferentes pessoas, entre governos, entre entidades por um meio heterogêneo de dispositivos. Todavia, ao nos conectarmos nesse meio de comunicação estamos sujeitos a riscos.
Para nos conectarmos ao ciberespaço precisamos de meios físicos, sistemas operacionais, sistemas, protocolos etc. e muitos deles não são seguros por padrão. Para compreendermos melhor o que vem a ser toda essa interconexão temos que relembrar o conceito básico de comunicação (KIM; SOLOMON, 2014). A comunicação, de modo geral, é dividida da seguinte forma, como vemos a seguir.
ü Emissor: responsável em enviar as informações. Por exemplo, pode ser uma pessoa querendo mandar um e-mail para alguém;
ü Canal de comunicação: é o meio físico pelo qual a informação é trafegada. Exemplo: cabo de par trançado, cabo de fibra óptica e backbone etc.
ü Protocolo: é uma linguagem comum para quem emite e para quem recebe a informação. Por exemplo, estamos usando a língua portuguesa;
ü Receptor: recebe a informação passada usando todas as definições anteriores.
Para o nosso contexto da Segurança da Informação, por exemplo, as informações trafegadas podem usar um canal de comunicação da Internet como a pilha de protocolos O TCP/IP ( Transmission Control Protocol/Internet Protocol ) que é dividido em quatro camadas, a saber: Aplicação, Transporte, Rede e Interface de Rede (KIM; SOLOMON, 2014). Cada uma dessas camadas irá interagir com diferentes abstrações como a baixa, mais compreensível a nível de máquina ou alta, mais compreensível para o ser humano.
Para se ter uma ideia, a Interface de Rede irá se comunicar a nível de hardware , enquanto a Interface de Aplicação seria, por exemplo, um software de gerência de recursos humanos. Os dados trafegados chegam na camada mais inferior (Interface de Rede) e vai repassando as informações até a camada mais abstrata, a de Aplicação. E dentro de cada camada há inúmeros outros protocolos, cada qual com suas particularidades. Observe a figura a seguir.

Através do modelo de pilha de protocolos TCP/IP na camada de Aplicação (figura modelo) temos alguns exemplos de protocolos. Como exemplo bem simples, podemos destacar o HTTP ( Hypertext Transfer Protocol ). Podemos citar o Web service que é um servidor usado para transferir dados através de protocolos de comunicação em diferentes plataformas, independentemente das linguagens de programação utilizadas nessas plataformas. Ele é muito utilizado na comunicação webservice (serviços web – REST/SOAP ), porém, as informações transmitidas são visíveis no momento da comunicação (texto claro). Pensando em segurança, a pessoa com conhecimento técnico poderia interceptar essa informação e utilizá-la para o mal (KIM; SOLOMON, 2014).
A partir dessa premissa, há uma grande necessidade de proteger as informações geradas e em meio a essa necessidade nasce a Segurança da Informação (SI). Podemos defini-la como sendo um conjunto de tarefas que visa à proteção de sistemas de informação (sistema operacional, softwares , hardwares etc.) juntamente com seus dados. Veremos posteriormente que não precisaremos reinventar a roda, uma vez que podemos seguir normas/padrões internacionais que abrange a Segurança da Informação.
A pilha de protocolos do modelo TCP-IP tem um protocolo desempenhando uma determinada tarefa, contudo, existem três categorias que abarcam esses protocolos, são elas: protocolos de aplicação, protocolos de transporte e protocolos de rede. O IP se encaixa na categoria de protocolo de rede. Nessa categoria, os protocolos operam nas camadas física, de enlace de dados e de rede, no caso do modelo OSI e nas camadas de acesso à rede e Internet, no caso do modelo TCP-IP, sendo responsáveis por tarefas que transmitem informações sobre endereçamento e roteamento, verificação de erro e requisições de retransmissão (COMER, 2016).
O IP é responsável por identificar seu dispositivo eletrônico (que também inclui os computadores) ou mesmo um site conectado a uma rede (tal como a de Internet), de modo que essa identificação seja única e, por isso, chamamos de endereço IP. O endereço IP conta com duas versões, o IPv4 e a IPv6. O IPv4 é composto por uma sequência de números, divididos em quatro blocos de 8 bits (separados por um ponto final), que são representados por 32 bits ou 4 bytes, por exemplo: 189.58.55.99.
O IPv6 é formado por 128 bits, permitindo utilizar 2 elevado a 128 endereços, equivalente a 79 octilhões de vezes a mais a quantidade de endereços IPv4 e, portanto, muito mais endereços que o IPv4 que suporta 2 elevado a 32 endereços e que, por sua vez, foi idealizado quando não se imaginava que a rede mundial de computadores teria tantos usuários conectados à ela através de variados dispositivos eletrônicos (KUROSE & ROSS, 2013).
Com a utilização do IPv6 foi resolvido a limitação do dos IP(s). O IPv6 é representado por números em hexadecimal, seu formato conta com 32 caracteres organizados em oito quartetos de 16 bits separados por dois pontos, por exemplo, 8888:9999:AAAA:BBBB:CCCC:DDDD:EEEE:FFFF. Um exemplo de IPv6 válido na Internet seria 2001:0DB8:AD1F:25E2:CAFE:CADE:F0CA:84C1. Na notação hexadecimal, cada caractere possui 4 bits, isto é, 16 combinações, o que nos faz ter números de 0 a 9 e também caracteres de A a F, representando os números de 10 a 15, respectivamente (COMER, 2016).
Cada provedor de serviço de Internet (do inglês Internet Service Provider – ISP), tem uma cota de endereços IP e quem distribui essas cotas e julga conflitos é uma entidade chamada Internet Corporation for Assigned Names and Numbers (ICANN). Assim, o endereço IP tem a função de rotear e entregar pacotes dentro da rede. Ele pode ser público ou privado, pode ser dinâmico, isto é, atribuído temporariamente a cada conexão a uma rede, ou pode ser estático, isto é, fixo. A capacidade de identificar um dispositivo eletrônico em uma rede contribui para que haja comunicação e permite identificar a origem de atividades de usuários que, inclusive, podem estar ligadas a crimes.
A primeira parte do endereço IP identifica uma rede específica e a segunda identifica o host conectado a esta rede. Um host é qualquer dispositivo eletrônico conectado a uma rede, desde computadores, smartphones, impressoras, TVs, até um roteador. As partes que identificam a rede e o host variam de acordo com a classe a que este endereço pertence. A figura 2 demonstra essa separação de classes, sendo definidos os intervalos:
Classe A : 0.0.0.0 a 127.255.255.255 (por exemplo: 17.2.23.12). Permite até 128 redes, cada uma com até 16.777.216 dispositivos eletrônicos conectados.
Classe B : 128.0.0.0 a 191.255.255.255 (por exemplo, 185.4.11.48). Permite até 16.384 redes, cada uma com até 65.536 dispositivos eletrônicos conectados.
Classe C : 192.0.0.0 a 223.255.255.255 (por exemplo, 192.14.11.10). Permite até 2.097.152 redes, cada uma com até 256 dispositivos eletrônicos conectados.
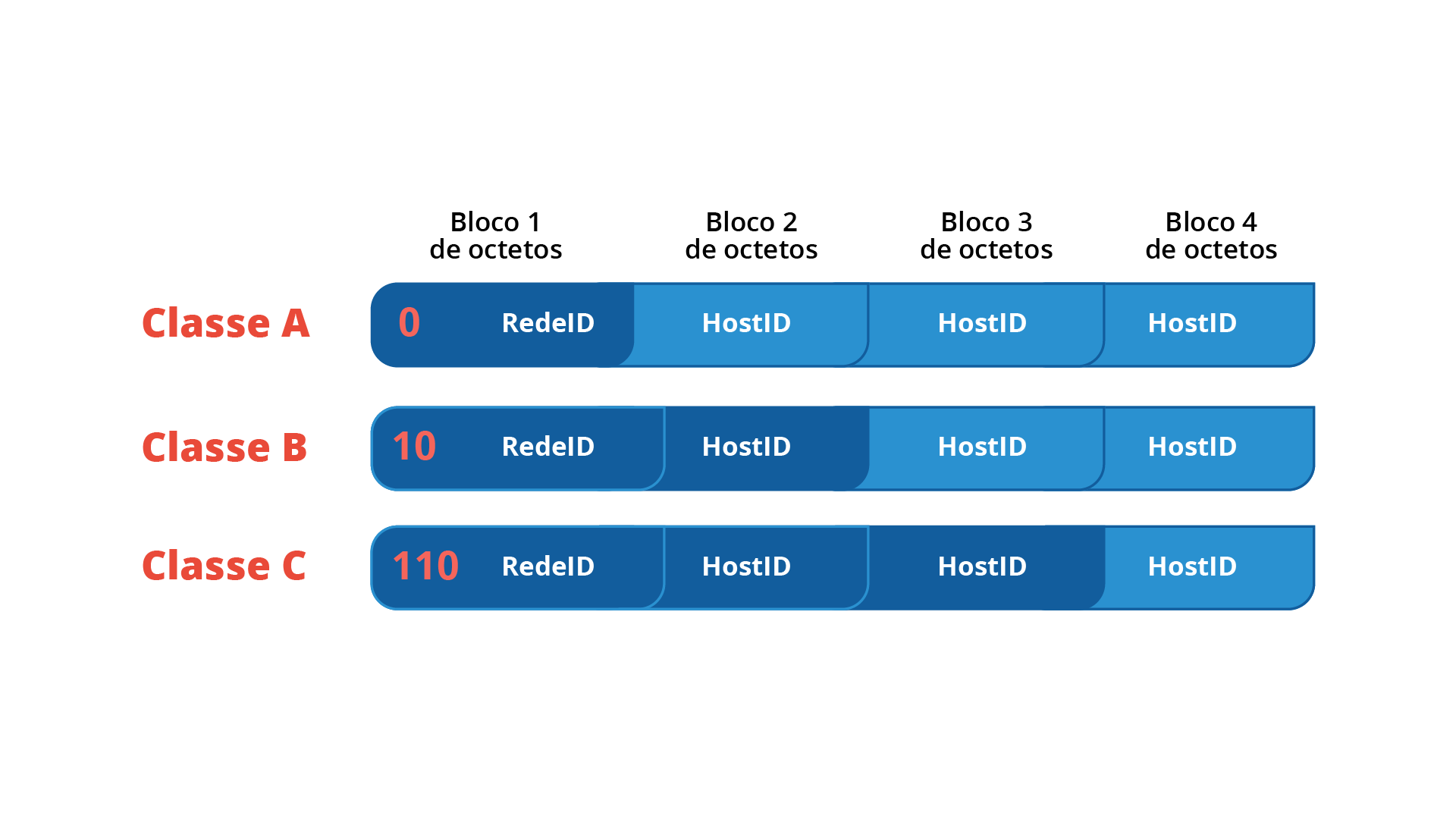
A Figura 1.4 traz a representação da separação de blocos de 8 bits , que compõem os 32 bits de um endereço IP, e definem as classes A, B e C de acordo com a utilização dos blocos para definição de identificador de rede e blocos para definição de identificador de hosts.
Devido a definição dos intervalos que separam as classes, a classe A inicia com um bit 0, a classe B com um bit 1 e um 0 e a classe C com dois bits 1 seguido de um bit 0. Cada bloco tem 8 bits, que podem variar entre os valores em decimal 0 (caso todos bits sejam 0) e 255 (caso todos os bits sejam 1). Essa divisão em octetos facilita a organização da rede, assim como o endereço de uma casa ou prédio, que é composto de uma rua e um número. Assim, a rede pode ser comparada ao bairro, enquanto o número da casa pode ser comparado ao host dentro da rede. A figura 3 traz exemplos de números de IP em binário e os decimais correspondentes (KUROSE & ROSS, 2013).
Existe também a classe D (224.0.0.0 até 239.255.255.255), usada para comunicação multicast (para um grupo determinado de dispositivos), e a classe E (240.0.0.0 até 255.255.255.255), reservada para futuras aplicações ou experimentos. O endereço 127.0.0.1, utilizado para se referir ao próprio host, chamado de localhost. Em geral, quando um endereço começa com 127 indica uma rede reservada para testes. Além disso, o endereço 255.255.255.255 é utilizado como broadcast, isto é, para propagar mensagens para todos os hosts de forma simultânea. Ainda temos o IP 169.254.0.0, que é o IP que o Sistema Operacional atribui ao computador quando ele não está conseguindo receber um IP válido (não consegue acessar a rede), sendo, por exemplo, um indicador de que o modem ou roteador não está funcionando corretamente.
Podemos verificar que a classe A deve ser utilizada quando desejamos utilizar poucas redes, mas temos uma quantidade grande de hosts a serem conectados a elas. Já os IPs da classe B podem ser utilizados quando desejamos criar quantidades semelhantes de redes e de hosts. Enquanto os IPs de classe C podem ser utilizados para quando existe a necessidade de criar muitas redes com poucos hosts.
Alguns intervalos de endereços IP das classes A, B e C são privados, utilizadas em redes internas, significando que não podem ser utilizados pela Internet. Os intervalos são:
Classe A: 10.0.0.0 a 10.255.255.255;
Classe B: 172.16.0.0 a 172.31.255.255;
Classe C: 192.168.0.0 a 192.168.255.255.
Notoriamente, você pode verificar que pequenas empresas ou instituições iniciam suas redes com 192.168, já que geralmente não precisam de muitos hosts em cada rede (Classe C).
Além disso, cada rede IP pode ser dividida em sub-redes para vários fins de administração facilitada, melhor organização e questões de segurança. Você pode saber a divisão de classes porque decorou, mas o computador sabe qual é a classe do endereço IP por causa da máscara de rede. Ela é usada para determinar onde termina endereço da rede e onde inicia o endereço do host, principalmente em sub-redes. No entanto, quando não há divisão por sub-redes, utilizamos as máscaras default para cada classe. Assim, se a máscara de rede é 255.0.0.0, o computador entende que a classe na qual está inserido é a A, se a máscara de rede é 255.255.0.0 pertence a classe B e se a máscara de rede é 255.255.255.0 pertence à classe C (MORAES, 2010).
A importância do IP se dá ao passo que ele é o centro da comunicação através da Internet, porque todos os aplicativos utilizam o IP e ele funciona sobre todas as tecnologias de redes. A Internet parece uma enorme e única rede por causa dos softwares que implementam os protocolos e, para isso, todos os computadores e dispositivos devem usar um esquema de endereçamento uniforme, além de único. De acordo com Comer (2016), para garantir isso, o IP define um esquema de endereçamento independente dos endereços MAC. A diferença é que enquanto os endereços MAC são usados como destinos em uma LAN, os endereços IP são utilizados como destinos na Internet. Desse modo, para enviar um pacote pela Internet, um software que implementa o protocolo IP utiliza o endereço IP para transportar pacotes entre emissor (origem) e receptor (destino).
Em suma, os aplicativos se comunicam através de endereços IP. Portanto, quem fornece os endereços IP são os softwares que os implementam e não a rede. E isso acontece sem a necessidade de os aplicativos saberem o tipo de hardware de rede ou endereços MAC que estão sendo usados pelos aplicativos de origem e destino.
No próximo tópico você verá que outros protocolos estão envolvidos na transmissão de dados pela Internet, em específico a pilha de protocolos TCP/IP, e qual a relação deles com o IP.
O Transmission Control Protocol (TCP) é o principal protocolo de transporte utilizado na Internet. Diferente do protocolo UDP, o TCP promove o transporte e entrega confiável de dados. O protocolo TCP desempenha uma tarefa incrível, pois utiliza um serviço de datagramas, que são mensagens enviadas sem conexão e sem confirmação oferecidos pelo protocolo IP, e promove a entrega de dados confiável para programas de aplicação. Isso significa que o TCP pega mensagens não confiáveis e transporta-as de forma confiável até o destino. Para promover essa entrega confiável, o TCP compensa perdas, atrasos, duplicações, pacotes fora de ordem, tudo isso sem sobrecarregar a rede e os roteadores. Assim, o TCP define explicitamente o estabelecimento da conexão, a transferência de dados e o fechamento para oferecer um serviço orientado a conexão (KUROSE & ROSS, 2013).
Contudo, existe a nomenclatura TCP-IP, que se trata, na verdade, de uma pilha de protocolos de comunicação de computadores e dispositivos em rede, que recebe esse nome devido aos seus dois principais protocolos. O TCP-IP é, portanto, como um modelo, semelhante ao modelo OSI, em que cada camada é responsável por determinadas tarefas. Cada camada oferece uma série de serviços para a camada superior. A figura 4 mostra as camadas do modelo TCP-IP.
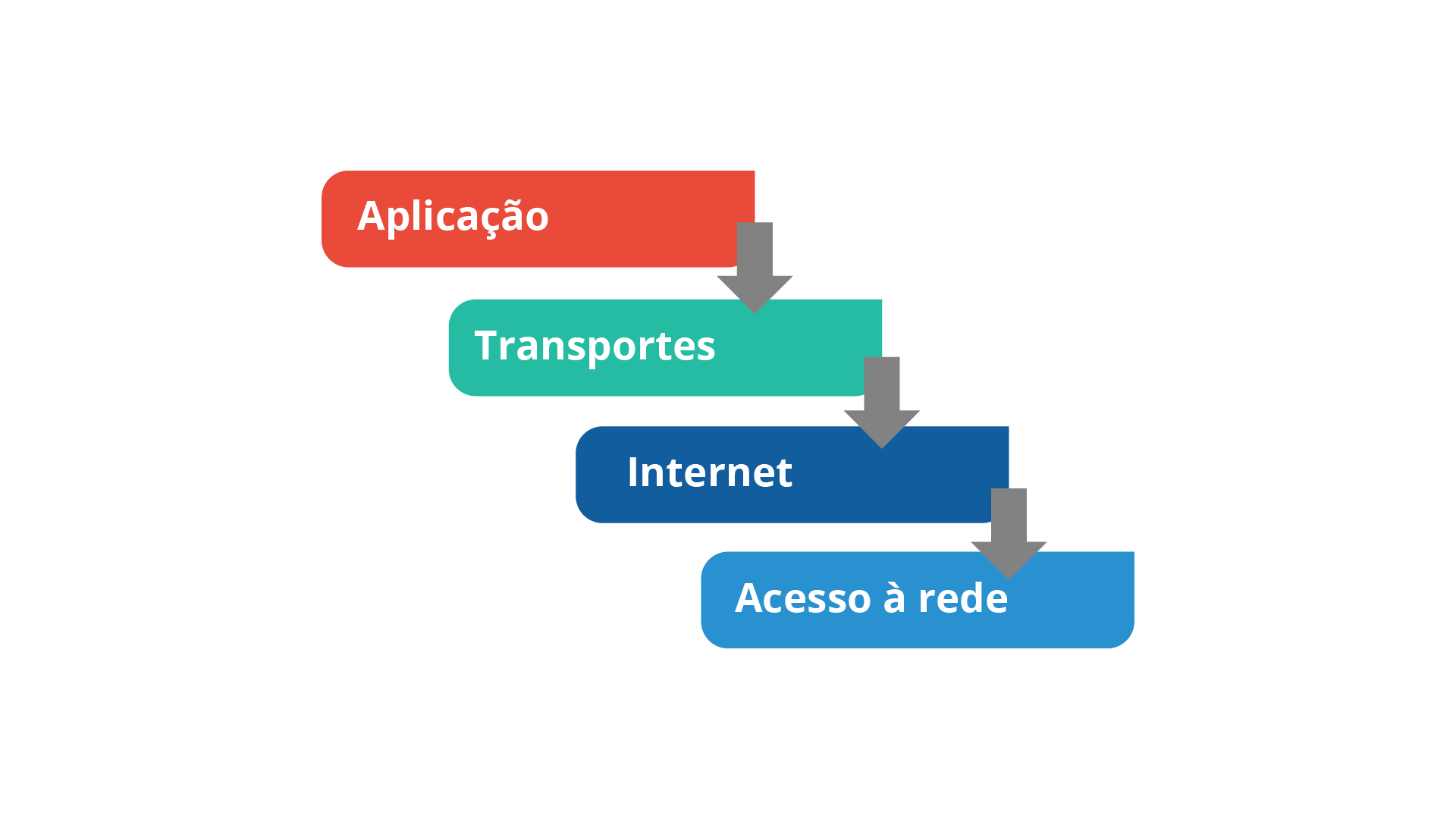
A figura 1.6 apresenta o Modelo TCP-IP de pilha de protocolos, onde cada camada fornece serviços para a camada superior, destacando a camada de Transporte, onde o protocolo TCP atua. O agente responsável pela camada de aplicação é o aplicativo, enquanto pelas camadas de transporte e de rede é o sistema operacional e o adaptador de rede é o agente responsável pela camada de interface. É importante entender que o TCP trabalha na Internet e, por isso, em cima do modelo TCP-IP, que possui quatro camadas e trabalha com diferentes protocolos em cada uma delas. No entanto, o foco aqui é descrever os serviços e funcionamento do protocolo TCP que trabalha na camada de Transporte. Assim, embora a base do modelo TCP-IP seja necessária, nosso objetivo neste momento é entender quais são as funções deste importante protocolo que é o TCP.
O TCP é um protocolo que oferece um transporte de dados com vários benefícios para o bom funcionamento de uma rede de computadores e dispositivos na Internet. Para entender como isso é possível, é importante entender as seguintes características do serviço oferecido pelo TCP às aplicações, segundo Comer (2016, p. 371):
Orientado à conexão: primeiramente o aplicativo deve solicitar uma conexão com o destino para depois utilizá-la para transferência de dados. Origem e destino devem se apresentar.
Comunicação ponto-a-ponto: cada conexão TCP tem especificamente dois pontos finais, isto é, unicast, entre uma única origem e um único destino.
Confiabilidade completa: há a garantia de que os dados que serão enviados através da conexão sejam entregues com integridade e em ordem.
Comunicação nos dois sentidos (full-duplex): permite a comunicação dos dados fluindo em qualquer direção, tanto da origem para o destino como o contrário, e que os dados sejam enviados a qualquer momento pelas aplicações.
Interface de fluxo (stream): fornece uma interface de fluxo na qual um aplicativo envia uma sequência contínua de octetos através de uma conexão. Não agrupa dados em registros ou mensagens e não garante a entrega dos dados em tamanhos iguais aos que foram enviados pelo aplicativo de origem.
Início de conexão confiável: o início da conexão das duas aplicações é confiável.
Finalização de conexão suave: antes de terminar a conexão de fato, há a garantia de que todos os dados tenham sido entregues e que ambos os lados concordaram em encerrar a conexão.
Portanto, o TCP deve oferecer um serviço fim-a-fim (entre um aplicativo em um computador e outro aplicativo em outro computador) confiável e eficiente. Para isso, deve tratar duplicatas, entregas fora de ordem, lidar com pacotes perdidos, evitar repetições, evitar inundação de dados e evitar congestionamento. Esses problemas são descritos a seguir, conforme Comer (2016, p. 372):
Comunicação não confiável: o TCP deve lidar com mensagens perdidas, duplicadas, corrompidas, entregues com atraso ou fora de ordem.
Reinicialização de um ponto envolvido: não deve haver confusão entre as sessões caso um dos dois pontos seja reinicializado por motivo de travamento, por exemplo.
Máquinas heterogêneas: um aplicativo funcionando em um computador equipado com um processador muito potente pode gerar dados de forma muito rápida a ponto de inundar (ou transbordar) uma aplicação que está rodando em um computador com processador lento.
Congestionamento na Internet: a transmissão de dados muito rápida faz com que comutadores e roteadores intermediários possam ser abarrotados de pacotes, causando o que chamamos de congestionamento.
Os protocolos de transporte são responsáveis por lidar com esses problemas complexos que podem atrapalhar a comunicação de forma efetiva. A seguir é descrito brevemente sobre como ocorre a comunicação ao utilizar o TCP e em seguida são descritos alguns mecanismos do TCP utilizados para resolver tais problemas.
Consideramos que cada mensagem é encapsulada no que chamamos de datagrama para serem transportadas através da Internet. Desse modo, o IP transfere o conteúdo para o TCP quando o datagrama chega no destino, contudo o TCP não lê e nem interpreta essas mensagens. Assim, o IP trata cada mensagem TCP como dados que precisam ser transportados. Enquanto o TCP trata o IP como um sistema de comunicação orientado a pacotes que fornece a comunicação entre os módulos TCP em cada extremidade de uma conexão. A figura 5 mostra como o TCP enxerga a Internet. Podemos verificar que a Internet toda é um sistema de comunicação que transmite e recebe mensagens sem interpretar o conteúdo delas.

A figura 1.7 mostra como o TCP vê a Internet em que cada ponto terminal de uma conexão virtual precisa de um software TCP, porém, os roteadores intermediários não precisam.
Primeiramente, como o TCP é orientado a conexão, existe o estabelecimento de uma conexão entre os processos de origem e destino para que a comunicação possa, de fato, acontecer. Em seguida, as comunicações podem acontecer nos dois sentidos em simultâneo, pois as conexões TCP são full-duplex. No entanto, as conexões poderão ser estabelecidas somente entre dois processos da rede, não existindo comunicações multicast ou broadcast.
Podemos abstrair o conceito de sockets para estabelecimento de uma conexão, em que um servidor TCP cria um socket para que fique esperando a solicitação dos clientes de conexão. É comum que o servidor crie um processo (ou thread) a cada nova conexão, assim, pode tratar a troca de mensagens por meio da nova conexão enquanto o processo original volta a esperar uma nova conexão. Enquanto isso, do lado do cliente, um socket também é criado para solicitar a conexão com o servidor. O cliente informa o endereço de rede do servidor e a porta utilizada para estabelecer tal conexão (KUROSE & ROSS, 2013).
Portanto, podemos concluir que o modelo de comunicação adotado pelo TCP é o cliente-servidor, contudo, ele também é utilizado como suporte para implementar outros modelos de comunicações em níveis superiores, como o modelo peer-to-peer.
Para resolver duplicatas e entregas fora de ordem é utilizada a técnica de sequenciamento, em que a origem adiciona um número de sequência a cada pacote e o destino armazena o número de sequência do último pacote recebido em ordem e armazena também uma lista dos pacotes que chegaram fora de ordem. Quando chega um pacote, o destino checa qual é o número de sequência. Se o pacote é o próximo esperado de acordo com a ordem que deve chegar, o software do protocolo entrega o pacote para a próxima camada mais alta e verifica a sua lista para ver se algum pacote adicional também pode ser entregue. Se o pacote chegou fora de ordem, o software do protocolo acrescenta o pacote na lista dos pacotes que chegaram fora de ordem.
O problema de duplicação também é resolvido com o sequenciamento, onde um destino verifica a existência de duplicatas ao analisar o número de sequência do pacote que chegou. Se o pacote já́ foi entregue ou se o número de sequência corresponde a um dos pacotes esperando na lista, o software descarta a nova cópia (COMER, 2016).
Para reenviar pacotes perdidos na rede o TCP utiliza do mecanismo de retransmissão. Esse mecanismo também é útil quando os pacotes chegam de forma errada. Para isso ele analisa o checksum de cada pacote, onde, para identificação é analisado o campo de número de sequência e para confirmação de entrega correta ao destino existe um campo de confirmação.
De acordo com Carissimi (2009), no TCP, a origem possui um buffer (temporizador) de transmissão que armazena os pacotes já transmitidos, porém que ainda não foram confirmados. Conforme as confirmações de entrega dos pacotes são recebidos pela origem, as cópias dos pacotes no buffer de transmissão são eliminadas, ao passo que o destino já recebeu o pacote. Assim, caso acontecer do pacote ser perdido ou descartado, não há confirmação de recebimento enviado do destino para a origem. Após um período máximo estipulado para espera, a origem detecta que o pacote foi perdido e então toma a providência de retransmitir o pacote.
Pode, ainda, haver erros de repetição quando ocorrem atrasos muitos longos na transmissão. Comer (2016, p. 374) explica:
Para evitar repetição, protocolos marcam cada sessão com uma identificação única (por exemplo, o horário no qual a sessão foi estabelecida) e requerem que essa identificação única esteja presente em cada pacote. O software do protocolo descarta qualquer pacote que chega com uma identificação incorreta. Para evitar repetição, uma identificação não deve ser reutilizada até́ ter passado um tempo razoável (por exemplo, horas).
Para evitar que um pacote transmitido por uma origem muito potente sobrecarregue (inunde) o destino que é mais lento, o TCP implementa o controle de fluxo. No TCP existe um campo de tamanho de janela que indica para a origem quantos bytes o destino possui disponíveis na sua janela de recepção. Isso significa que o destino pode informar a origem quantos dados ele ainda pode enviar sem que haja congestionamento. Existem técnicas para controle de fluxo, tais como a stop-and-go e o de janela deslizante. O stop-and-go, por exemplo, funciona com a origem transmitindo somente quando recebe uma mensagem de controle do destino, avisando quando está pronto para receber o próximo pacote.
O próximo tópico traz algumas informações básicas sobre autenticação na Internet, mostrando quais são os tipos de autenticação e como lidamos com elas em relação ao cuidado de manter a segurança em rede.
Em Ciência da Computação, a autenticação é um dos principais meios pelo qual se procura manter a segurança nos sistemas. Existe, de acordo com Stallings (2015), a autenticação de usuário e a autenticação por mensagem.
Autenticação por usuário: processo no qual é verificado se alguém é quem diz ser. Isso é feito geralmente no momento do login (acesso) em um software, inclusive sistemas operacionais.
Autenticação por mensagem: processo em que as partes que se comunicam verificam se o conteúdo de uma mensagem recebida não foi alterado e se a origem é quem deveria ser, isto é, autêntica.
No que diz respeito a autenticação por usuário, que verifica a identidade deste,Stallings (2015) afirma que pode ser feita de quatro maneiras, podendo ser apenas uma ou uma combinação delas, sendo:
Algo que o indivíduo sabe: pode ser uma senha, algum número de identificação pessoal que vem no seu smartphone novo, por exemplo (PIN – Personal Identification Number) ou resposta secreta a uma pergunta que você escolhe entre algumas pré-estabelecidas, como por exemplo “Qual foi o seu primeiro animal de estimação?”. Neste último caso, existem alguns tipos de desafios-resposta que os processos de autenticação utilizam, os bancos por exemplo, utilizam a data de nascimento do proprietário da conta.
Algo que o indivíduo possui: chaves criptográficas, cartões de senha eletrônica, smart cards, chaves físicas. Esse tipo de autenticador é conhecido como token.
Algo que o indivíduo é (biometria estática): reconhecimento por impressão digital, retina e face.
Algo que o indivíduo faz (biometria dinâmica): reconhecimento por padrão de voz, características de escrita manual e ritmo de digitação.
Uma quinta maneira que pode ser utilizada para autenticação de usuário é onde o usuário está (localização). O banco, por exemplo, pode considerar estranho você estar fazendo mais de uma ou duas compras em um país diferente do de origem e bloquear seu cartão por segurança. Existe aplicativo de banco que permite você marcar uma opção que diz que você está fora do país ou está viajando e, assim, você poderá fazer quantas comprar quiser, pois o banco saberá que é você, já que avisou que iria viajar ao marcar determinada opção no aplicativo.
E outro modo que não se encaixa em nenhuma dessas categorias acima, mas é utilizada para atestar que não tem bot algum tentando acessar determinado sistema, é o captcha. Uma sequência de caracteres dentre maiúsculos e minúsculos são exibidos em uma imagem e você deve digitá-los para poder prosseguir a navegação.
Cada maneira de autenticação tem seus problemas. Um invasor pode adivinhar ou roubar uma senha, como também pode forjar ou roubar um token. O próprio usuário pode esquecer uma senha ou perder um token e alguém o utilizar indevidamente, se passando pelo proprietário. Além disso, os sistemas também podem estar vulneráveis a falhas de segurança. Quanto aos leitores biométricos, digitais podem não estar legíveis, pode haver falso positivo e falso negativo, além de um custo maior. E quando falamos de rede, as autenticações mais comuns são chaves criptográficas e algo que o indivíduo sabe, principalmente senhas.
Na Internet, há algum tempo, criar senhas se tornou algo mais valorizado pelas empresas e elas mesmas implantaram mecanismos que avaliam se sua senha, no momento de criação, é fraca, média ou forte. Assim, não é possível criar uma senha fraca. Com o avanço da capacidade de ataques, se tornou comum exigir autenticação de dois ou mais fatores, em que, além da senha, algum token ou mesmo a opção de biometria por digital e em casos mais sofisticados, de reconhecimento facial. As fabricantes de smartphones já utilizam esses dois últimos mecanismos. Enquanto os bancos utilizam em seus aplicativos, além da biometria de digital, opção de envio de SMS com um código para confirmar transações online.
Além de todas maneiras de autenticação por usuário, existem técnicas de criptografia que buscam proteger não apenas senhas, como conteúdos em arquivos, pastas e sistemas. No entanto, dificilmente alguma técnica é 100% segura.
Uma rede sem fio (Wi-Fi), por exemplo, pode ser o berço de diversos ataques sem que você perceba. Por exemplo, um criminoso pode simular ser um hotspot de uma Wi-Fi legítima, podendo observar como está o tráfego na rede e as chaves de segurança dos usuários conectados. Assim, eles acessam dados confidenciais dos usuários. Existem meios de autenticação para redes sem fio, tais como chave WEP, WPA, WPA2, autenticação em um banco de dados central, autenticação de fator duplo, entretanto, manter uma Wi-Fi o mais segura possível ainda é um desafio para os profissionais de TI.
Outro modo muito utilizado é o phishing, quando o criminoso manda um e-mail, parecendo ser originalmente do seu banco, por exemplo, solicitando que você acesse links que o levam a inserção de dados confidenciais através de formulários.
Muitas das formas de tentar quebrar a segurança de autenticação são de tentativa e erro. Desse modo, softwares podem ser criados para tentar, na força bruta, acessar um sistema, isto é, tentando diversas combinações de caracteres (letras, números e símbolos). Existem programas para quebrar senhas específicas da Internet que utilizam protocolos HTTP, FTP e outros de e-mail, existem programas que quebram senhas de arquivos advindos de editores de texto, de compactadores de arquivos, de arquivos em pdf.
As maneiras de autenticar usuários e proteger conteúdo, mesmo que em constante evolução pelos profissionais de TI e empresários, possuem falhas e, por isso, os usuários podem contribuir para essa segurança das informações ao tomar determinadas atitudes. Tais atitudes podem ser: criar senhas fortes, aderir ao acesso com biometria, utilizar aplicativos que bloqueiam o acesso aos aplicativos importantes com senha, não acessar ou realizar download em sites suspeitos, verificar se o link do site é realmente oficial, ficar atento a ligações que dizem ser de bancos que solicitam informações que os bancos informam que não solicitam por telefone ou e-mail, verificar os endereços de remetente de e-mails adequadamente para não clicar em links que podem exigir informações confidenciais ou mesmo instalar malwares em seu dispositivo, dentre outros cuidados.
Na internet temos vários tipos de protocolos para nós comunicar, entre os mais comuns meios de comunicação está o nosso e-mail, páginas da internet, chat de bate-papo, troca de mensagens, troca de arquivos entre outros, sem esta funcionalidade não teríamos tido a grande expansão da internet, e com ela também podemos identificar as vulnerabilidades existente neste ambiente da internet, vamos exercitar um pouco nosso conhecimento sobre protocolos da internet.
Enumere a coluna II de acordo com os protocolos da coluna I, associando os protocolos da internet às suas respectivas funções.
Assinale a sequência correta que atende aos respectivos protocolos.
Ao longo deste capítulo apresentaremos mais detalhes de como a Segurança da Informação está estruturada e que tipo de garantia nos oferece.
Precisamos ter um bom entendimento sobre a segurança da informação e como ela afeta as atividades rotineiras na internet e em nossos dados pessoais, para isso temos que entender os conceitos primordiais, tanto da segurança como as situações possíveis de fraudes e ameaças na web.
Antes de estudarmos mais sobre a SI vamos conhecer algumas definições/termos que são bastante utilizados. Muitas dessas definições/termos são oriundas de normas da área de Segurança da Informação (HINTZBERGEN
et al
., 2018).

A priori , as normas são um conjunto de padrões de boas práticas e a seguir apresentamos alguns desses termos.
Analise o trecho a seguir:
Uma técnica de “______________” foi detalhadamente descrita em um artigo e em uma apresentação feita para o International HP Users Group, Interex, em 1987. O uso do nome em si foi primeiramente atribuído ao um notório spammer e hacker em meados da década de 1990, Khan C Smith. Além disso, de acordo com registros da Internet, a primeira vez que o ______________ foi publicamente usado e registrado foi em 2 de janeiro de 1996, muitos usuários foram vítimas de muito material enviado por e-mail não solicitado. A menção ocorreu em um fórum de discussão da usenet chamado AOHell. Na época, a America Online (AOL) era o principal provedor de acesso à Internet e tinha milhões de acessos todos os dias.
Entre uma das ameaças que estamos expostos na web há uma que realmente impacta suas ações e compromete sua credibilidade nos ambientes virtuais, assinale a alternativa que apresenta esta ameaça:
A Segurança da Informação visa a proteger as informações, deixando-as seguras de diferentes ameaças. Para que isso ocorra, a SI deve possuir uma garantia de princípios que permitem tal ação. Basicamente, a SI está fixada sobre três alicerces (princípios) (KIM; SOLOMON, 2014), como vemos a seguir.
Muitos autores se referem a esses três termos como o triângulo ou tríade, ou simplesmente CID, um acrônimo de Confidencialidade, Integridade e Disponibilidade. Sempre que estivermos falando sobre segurança de informações teremos que ponderar esses três princípios. Após a sua definição é possível definir estratégias e controles para a segurança dos dados.
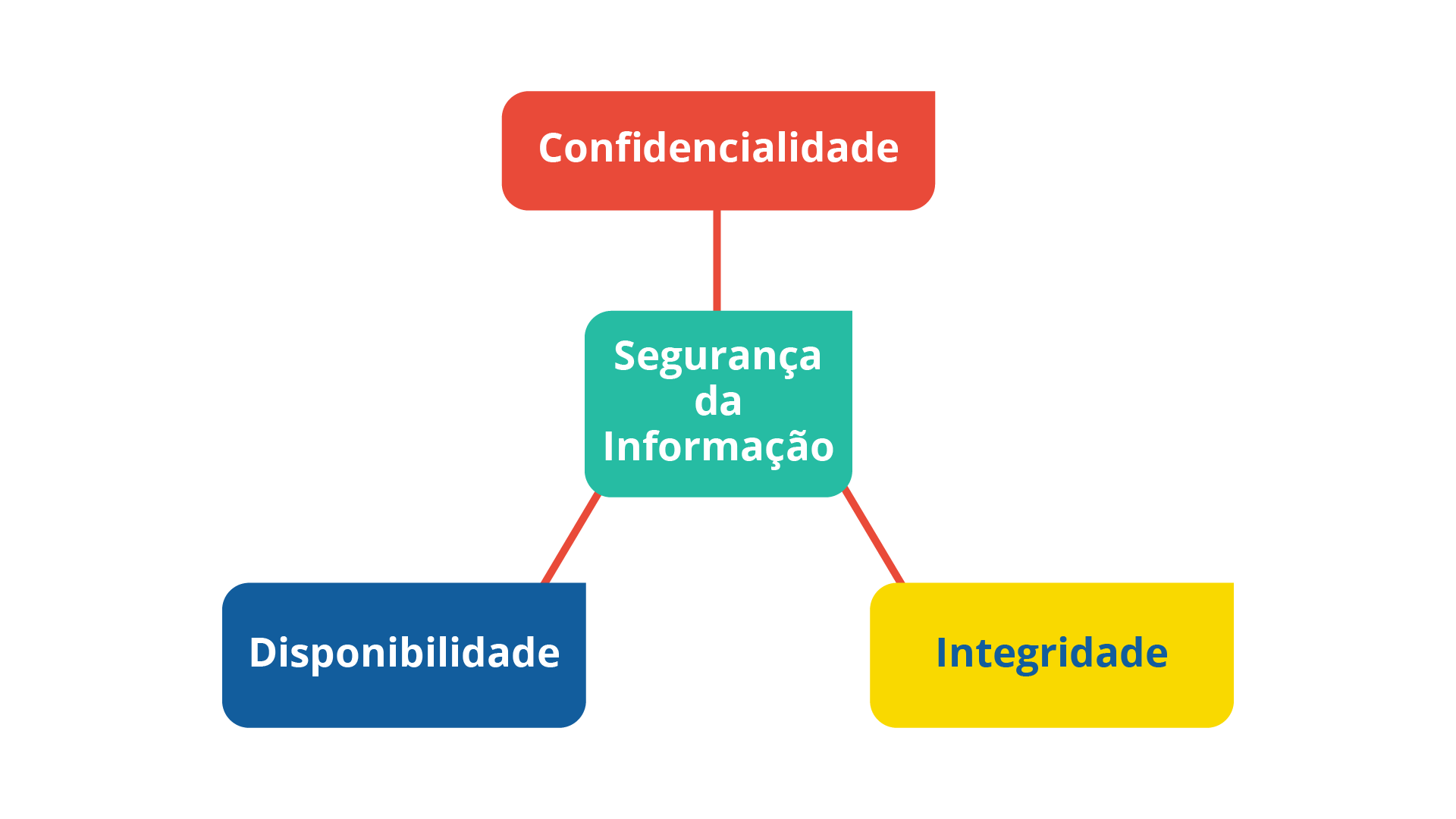
A seguir, descreveremos mais alguns pontos importantes sobre cada um dos princípios.
Disponibilidade, acredito que esse seja o termo que mais nos afeta uma vez que, diariamente, temos acesso a diversos serviços. Pense sobre o pacote de dados de seu celular, por exemplo, que você adquiriu para acessar a Internet em qualquer local, mas certo dia você acabou viajando para uma cidade vizinha que não tinha sinal e sua Internet não funcionou. O que adiantou você pagar um valor elevado se quando precisa ele não está disponível? A qualidade desse serviço é expressa pelo tempo disponível ao usuário (KIM; SOLOMON, 2014). Vejamos algumas dessas medidas de tempo a seguir.
Como dito anteriormente, existe um contrato ou Acordo de Nível de Serviço ( Service Level Agreement - SLA) na prática é tudo que um prestador de serviços se propõe a entregar para um cliente dentro de algumas regras homologadas em contrato, envolvendo o tempo em que o serviço vai ser feito, a qualidade com a qual vai ser entregue, como problemas devem ser reportados e a lista pode ficar maior dependendo do tipo de serviço. . Por exemplo, dentro de um mês e com disponibilidade de 99,93% quer dizer que haverá 30 minutos dedicados a reparos.
Integridade, esse princípio lida com a qualidade dos dados. Um dos bens mais preciosos de uma organização são seus dados. Os dados armazenados podem ser ações em uma bolsa de valores, cálculos de projetos secretos, patentes, movimentação bancária etc. Imagine uma agência bancária que não tem nenhum controle de suas informações. Em um dia você poderia estar milionário e em outro ter feito um empréstimo. Nesse princípio de segurança temos que assegurar que os dados são reais, válidos e que não sofreram nenhuma alteração sem autorização (KIM; SOLOMON, 2014).
Confidencialidade, este princípio protege o acesso das suas informações de outras pessoas que não sejam pertinentes. Atualmente, muitas pessoas deixaram de comprar produtos em lojas físicas para comprarem produtos on-line . Isso se dá pela praticidade, pelo bom preço, pelas opções de produto, tipos de entrega etc. Porém, pode acontecer de que sejam expostos seus dados pessoais, como número de cartão de crédito e CPF, por exemplo, a sites falsos/terceiros. Em consequência disso, outras pessoas poderão se passar por você e realizar novos débito, por isso a confidencialidade é bastante crítica, visto que terceiros podem assumir nossa identidade e causar grandes transtornos. Um termo bastante usado para esse assunto é a Engenharia Social, em que pessoas são capazes de obter qualquer tipo de informação. Logo, medidas devem ser criadas para minimizar tais ataques (KIM; SOLOMON, 2014), as quais podemos ver abaixo.
Não permitir o acesso aos dados é só uma etapa desse processo. Deve-se realizar uma série de controles com base em normas, a exemplo da ISO 27001. Vejam os exemplos:
Por exemplo, é bem possível que você já tenha enviado dados pessoais por e-mail . Essa é uma péssima opção. Os dados trafegados por e-mail , dependendo do provedor, não possuem nenhum tipo de segurança. Em outros casos, o próprio uso de Inteligência Artificial pode ler o conteúdo de seu e-mail . Para contextualizar, o próprio Google possui frases prontas no final do e-mail para que você responda de forma rápida e perceba que as respostas estão de acordo com o conteúdo do e-mail . Se o corpo do e-mail contém uma informação de certo agendamento, no final, na frase gerada pela Inteligência Artificial, haverá textos como: “Confirmado”, “Não posso nesse dia”, “Obrigado” etc.
Os ataques de negação distribuído de serviço, DDoS, são criados para deixar um sistema ou servidor inoperante, sem acesso para os usuários. Essa técnica é feita invalidando os servidores de conteúdo, gerando uma sobrecarga nas requisições. Temos um exemplo muito noticiado na mídia digital, quando as empresas Sony PlayStation Network e a Microsoft Xbox Live ficaram indisponível, fora do ar por um bom tempo, isso devido à ataques de DDoS.
Fonte: Fonte: PAYÃO, Felipe. Hackers realizam o maior ataque DDoS da história . 2016. Disponível em: <Hackers realizam o maior ataque DDoS da história>. Acesso em: 08 fev. 2020.
Sempre desconfie e nunca passe seus dados a ninguém ou a sites desconhecidos. Antes de realizar qualquer compra on-line verifique se a empresa é séria ou se aquilo é algum golpe. Lembre-se de que as pessoas pegam seus dados a partir de uma isca, um produto muito barato, serviços com recursos ilimitados etc. Fique sempre atento!
Ao observar os princípios da Segurança da Informação, perguntamos quais domínios são afetados dentro da TI (KIM; SOLOMON, 2014). Em resumo, pode-se dizer que são sete, como vemos a seguir:
Entre os conceitos da tríade da segurança da informação confidencialidade, integridade e disponibilidade - CID, assinale a alternativa que identifica o tempo de recuperação de um sistema crítico?
O Hexagrama Parkeriano é outra definição dos princípios da Segurança da Informação. Apesar de possuir os mesmos três atributos do CID, ele ainda acrescenta outros três atributos (HINTZBERGEN et al ., 2018). Logo, o hexagrama Parkeriano é definido em:
Como discutido anteriormente, já conhecemos os termos da CID - confidencialidade, integridade e disponibilidade. Agora, veremos sobre os outros três termos conhecidos do Hexagrama Parkeriano.
Apesar de o Hexagrama Parkeriano incluir mais três propriedades aos princípios clássicos (CID), eles não se sobrepõem. Podemos dizer que são complementares, mas se usa com mais frequência a tríade CID como uma referência para definir os princípios da Segurança da Informação.
Os vírus de computador são códigos maliciosos, identificados como malware, que são desenvolvidos usando estratégias de invasão e infiltração, podendo até duplicar-se para outros usuários, burlando as defesas dos usuários descuidados, os danos causados podem ser desde um comprometimento do sistema operacional até a destruição ou modificação de arquivos encontrados. Um exemplo dos primeiros vírus foi o “sexta-feira 13”, que era ativado em sempre nesta data, esse vírus tinha a função de inflar, aumentar o arquivo de tamanho até ser corrompido. Atualmente, os vírus de computador evoluíram e ganharam novas funcionalidades, eles podem fazer varredura de nos diretórios e se passar por algum aplicativo original, não despertando os alertas de segurança do sistema ou do próprio usuário. Acompanhando a evolução dos vírus de computador surgem os antivírus que englobam não só a detecção como a varredura, proteção na navegação, permissões de usuários menores e firewall no pacote de antivírus, isso lógico um antivírus proprietário. Nesta linha de pensamento o que poderá ser incorporado aos softwares de antivírus para garantir uma maior segurança aos usuários?
Fonte: Elaborado pelo autor.
Vimos que o Hexagrama Parkeriano é uma complementação do Princípio da Segurança da Informação. Além disso, ele dá mais detalhes sobre o dado. Ou seja, passamos a conhecer o grau de importância do mesmo. Conhecendo a sua utilidade, propriedade e acesso.
O hexagrama Parkeriano soma mais três atributos aos três atributos clássicos da tríade de segurança da informação CIA (confidentiality, integrity, availability ou em português: Confidencialidade, integridade e disponibilidade; estes são os princípios fundamentais da segurança). No hexagrama Parkeriano quais são os três atributos inseridos na tríade da segurança da informação?

Ano: 2015
Comentário: Alan Turing, conhecido como um dos pai da computação moderna e da inteligência artificial, foi um matemático e cientista da computação britânica. Através de seus experimentos ele foi capaz de criar a “máquina de Turing”, princípio do computador moderno. Seus esforços com os aliados na segunda guerra mundial, foi em quebrar os códigos da máquina enigma, criada pelos alemães, . Seu trabalho deu origem ao Colossus máquina que decodificava os códigos da enigma, com o fim da segunda guerra, as bases tecnológicas desenvolvidas serviram de base para a evolução dos computadores modernos da primeira geração, tanto o hardware como o software evoluíram neste período. Assista ao trailer para saber mais.

Richard A. Clarke e Robert K. Knake
Editora: Brasport
ISBN: 978-85-7452-737-6
Comentário: “Guerra Cibernética: a próxima ameaça à segurança e o que fazer a respeito” (2015), de Richard A. Clarke e Robert K. Knake. O livro aborda o cenário atual da guerra cibernética, ponderando as armas computacionais e seus impactos nos diversos meios, como sociedade, governos, militares etc.
A quantidade de dados cresce exponencialmente a cada momento, devemos nós preocupar com o armazenamento e segurança dos dados. A informação é a caracterização mais próxima dos dados que conhecemos. O conhecimento é uma relação entre várias informações. Um SGBD - (Sistema de Gerência de Banco de Dados) garante a propriedade ACID - Atomicidade, Consistência, Isolamento e Durabilidade. A comunicação no ambiente da rede envolve excepcionalmente emissor, canal de comunicação, protocolo e receptor. Grande parte das comunicações entre computadores, servidores são através do "texto-limpo". Os princípios fundamentais da Segurança da Informação são disponibilidade, integridade e confidencialidade. Os sete domínios afetados pela Segurança da Informação são usuário, estação de trabalho, LAN, LAN/WAN, WAN, acesso remoto e sistema.
O Hexagrama Parkeriano é uma complementação dos princípios da SI. São eles: confidencialidade, posse ou controle, integridade, autenticidade, disponibilidade e utilidade.
ABNT NBR ISO/IEC 27001. (2006). Tecnologia da informação – Técnicas de Segurança - Sistemas de gestão de segurança da informação - Requisitos . Rio de Janeiro: Associação, Brasileira de Normas Técnicas.
CARISSIMI. Alexandre da. S.; ROCHOL, Juergen; ZAMBENEDETTI, Granville. Redes de computadores [recurso eletrônico] . Porto Alegre: Bookman, 2009.
COMER, Douglas E. Redes de computadores e internet [recurso eletrônico] . 6ª edição. Porto Alegre: Bookman, 2016.
Hintzbergen J. et al . Fundamentos de Segurança da Informação , com base na ISO 27001 e na ISO 27002, Brasport, 2018.
Kim D. e Solomon M. G. Fundamentos de Segurança de Sistemas de Informação , LTC, 2014.
KUROSE, J. F.; ROSS, K. W. Redes de computadores e a internet : uma abordagem top-down [recurso eletrônico]. 6ª edição. São Paulo: Pearson Education do Brasil, 2013.
Marquesone, Rosangela de Fátima Pereira - Big Data : Técnicas e tecnologias para extração de valor dos dados, São Paulo, Editora Casa do Código, 2016
MORAES, Alexandre F. Redes de computadores: fundamentos . 7ª edição. São Paulo: Érica, 2010.
Sêmola, Marcos - Gestão da segurança da informação : uma visão executive – Rio de janeiro: Editora Elsevier, 2014.
STALLINGS, William. Criptografia e segurança de redes : princípios e práticas. 6ª edição. São Paulo: Pearson Education do Brasil, 2015.